1. 来源
AAAI 2018
2. 作者信息

3. 概要
基于KG的QA中通常会有多个阶段,例如关键实体识别,路径搜索。本文提出了一种端到端的变分学习算法来处理QA中的关键实体识别中可能产生的噪音和多跳的关系。本文提出的方法能够在测试数据集上达到很好的效果,此外,本文还提出了一个新的测试数据集,其中包含多条关系的问题,在这个数据集上,本文提出的模型也能得到很好的效果。
4. 模型
本文提出的模型为variational reasoning network(VRN),其结构如下所示
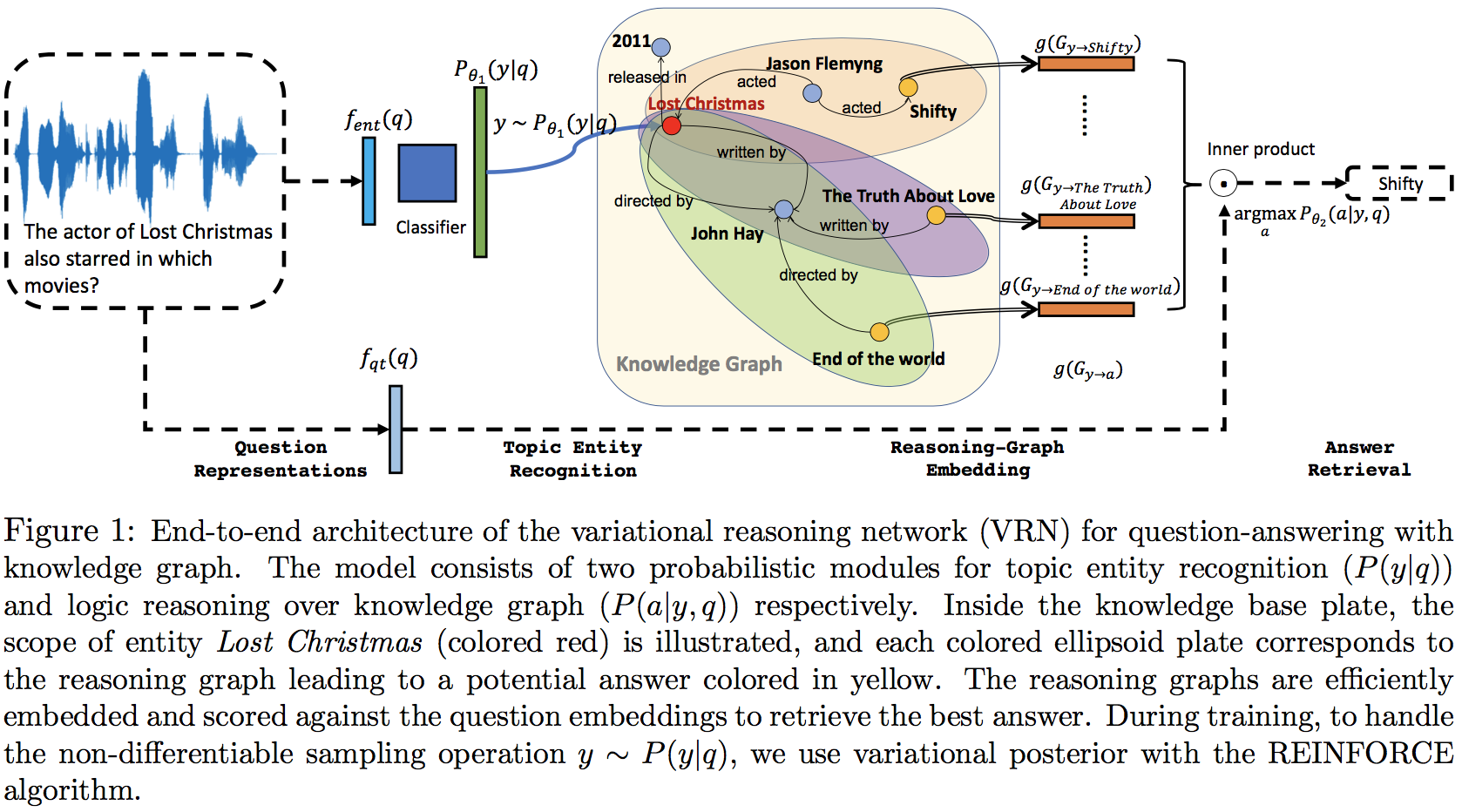
在模型中,答案在问题下的条件概率可以写成
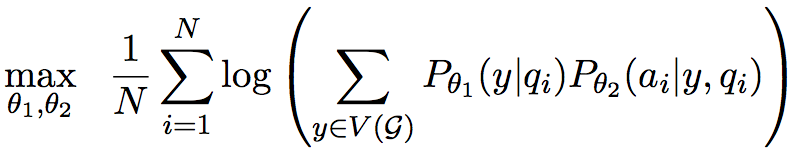
其中q表示问题,a表示答案,y表示问题中对应的主实体
其中包含了两个主要的概率模块Topic entity recognition以及logic reasoning
4.1 Probabilistic module for topic entity recognition
这部分计算得到问题中的主实体y在问题q下的条件概率
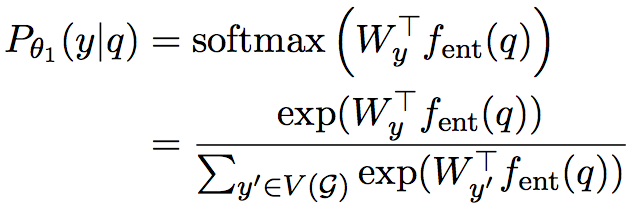
其中 $ f_{ent} $ 是一个神经网络,将问题映射到一个定长的向量,具体的实现可以是RNN(文本输入),CNN(声音输入)
4.2 Probabilistic model for logic reasoning over knowledge graph
这部分计算在问题q以及主实体y下,答案a的条件概率
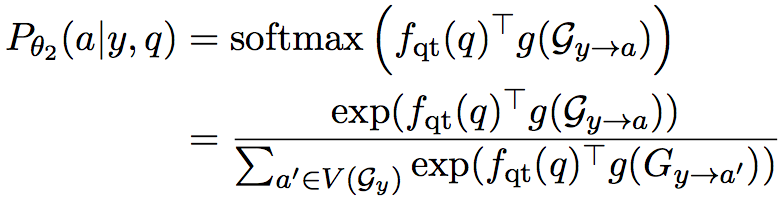
其中 $ f_{qt} $ 是一个神经网络,将问题映射到一个定长的向量,$ V(G_y) $表示从y节点出发,通过一定量关系能到达的节点的集合,$ g(G_{y\rightarrow a}) $ 表示知识库中实体y到实体a路径的一个向量表示(这个路径中可能有多个关系,也可能只有单个关系)
$ g(G_{y\rightarrow a}) $可以通过以下迭代过程计算得到
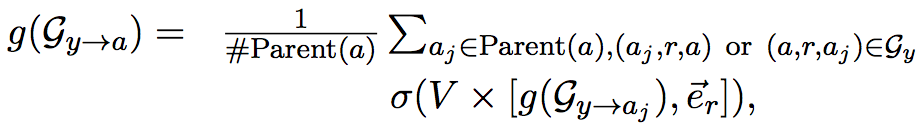
迭代过程的终止条件是
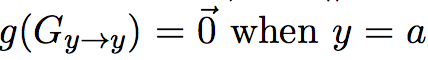
注意到,在整个迭代的过程中,对于一个主实体y,可以一次性计算出$ V(G_y) $中所有节点对应的值(实际上就相当于遍历一遍所有的节点),时间复杂度为
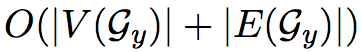
通过这种方式logic reasoning概率模型的分母能够快速地计算出来
4.3 训练
目标函数是一个复杂的概率分布,并且其中包含隐变量y,所以可以通过变分推测转化为ELBO问题的求解
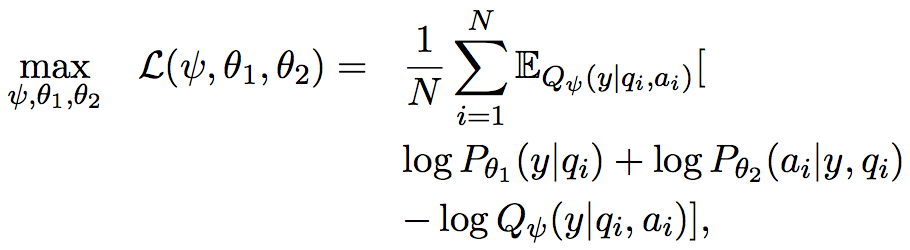
其中
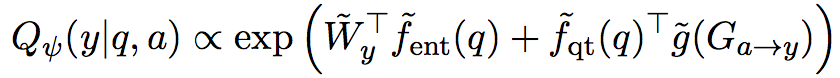
公式中带~的符号和之前的大小一致,但是是不同的参数,且最后对所有的y进行归一化计算
训练中借助于REINFORCE算法,对Q的参数进行更新
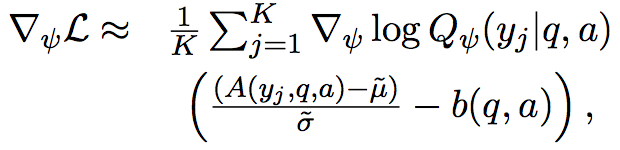
其中$ \tilde{\mu} $和$ \tilde{\sigma} $是在计算过程中A的均值和方差的一个moving agerage,实际上起到了momentum的作用,一定程度上能够减少PG的high variance问题
整体的算法如下

4.4 测试
测试过程中,为了减少搜索的复杂度,使用了beam search,先找到最合适的k个主实体,然后再求解答案
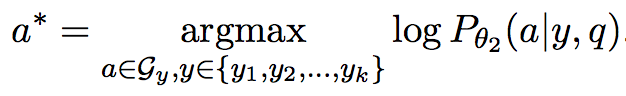
在实验中,使用了k=1(等价于贪心),即可得到不错的结果
5. 实验结果
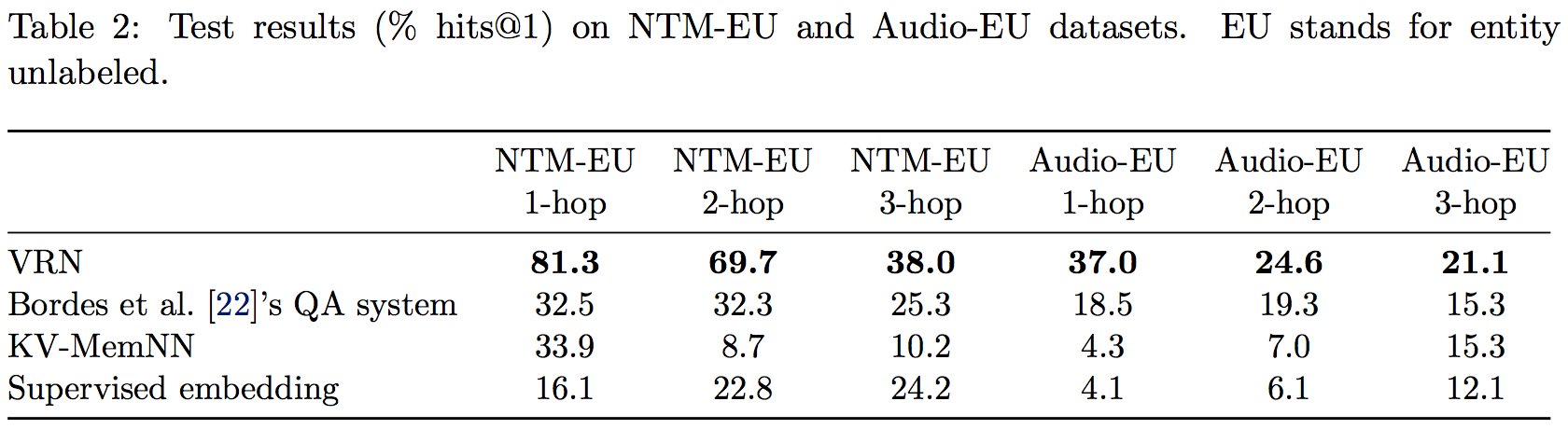
本文提出了一个新的QA测试数据集MetaQA(Movie Text Audio QA),其中包含超过400K的问题,其中涵盖了单关系以及多关系的问题
实验结果如下所示
6. 个人总结
之前的一系列KBQA的方法,其实都是多个stage的方式,需要找到主实体,再从主实体出发找到答案(可能还会有额外的步骤再添加一些限制)。而这篇论文试图通过一个端到端的方式来实现KBQA,具体的做法是将主实体的发现当作一个离散的过程,使用REINFORCE算法进行优化求解。另外一个比较有意思的点在于对KB的图结构信息的处理,本文并没有将整个KB先训练得到embedding,而是选择对于每次查询,临时计算从主实体出发的一小块子图进行embedding(实际上的到的是路径对应的向量)。
和STAGG以及HR-BiLSTM这些模型(这两个模型在webquestion上的效果很好)比起来,本文的VRN在表达能力上是有一定的局限的(缺少了前面那些模型中添加额外限制的操作,只考虑了找主实体、从主实体出发找答案的过程),感觉如果在webquestion这类的数据集上,并不一定能够超过前两个模型的效果。
-
前一篇
Sequence-to-Sequence Learning as Beam-Search Optimization -
后一篇
Some methods for text summarization