1. 来源
EMNLP 2016
2. 代码
https://github.com/harvardnlp/BSO
3. 作者信息

4. 概要
本文提出了一种seq2seq模型的训练方法,这种方法通过计算全局的序列分数来避免传统的基于MLE的方法中出现的问题,如label bias和exposure bias。在实验中,本文提出的方法在多个seq2seq任务中都能比其他的baseline方法取得更好的效果
5. 介绍
Seq2seq最为普遍的训练方法是将decoder中序列的生成过程当作是一个条件语言模型,即在输入序列和到当前时刻之前的标签历史输出序列的条件下计算得到当前要生成的词的概率分布
这个过程中有以下的问题
-
Exposure bias。在训练过程中,词的生成是基于标签历史输出序列,但是在测试过程中,词的生成是基于历史输出序列,这样训练和测试的数据分布是不一致的
-
Loss-evaluation mismatch。在训练过程中,损失函数统计的是每个词的损失的和,即是对序列中的词进行评估,但是BLEU等指标是对整个序列进行评估
-
Label bias。每一个时刻,词的产生都是通过局部归一化后的概率分布进行采样。
6. 方法
本文提出的方法是Beam Search Optimization(BSO),具体的做法是在训练的过程中也使用beam search,并保证标签输出序列一定出现在beam search的k-top中。
为了进行beam search,首先定义了函数f
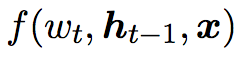
这个函数计算得到在t时刻生成词 $ w_t $
对应的score,实际上这个函数和传统训练方法中计算生成每个词生成概率的函数完全相同,只是去除了归一化的softmax层
6.1 Search-Based Loss
Search-based loss的定义如下
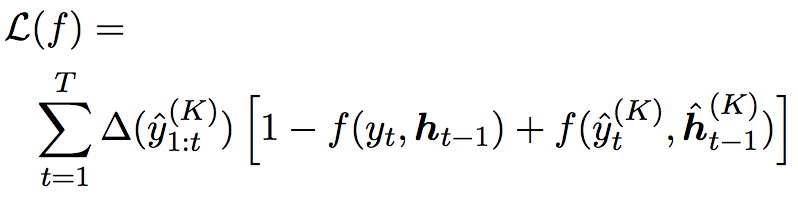
其中,带hat标记的符号表示模型历史产生的序列数据,而不带hat标记的符号表示标签序列数据。这是一个margin loss,search-based loss惩罚了标签序列数据不出现在beam search top-k结果中的情况,公式中
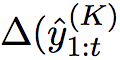
控制对一些标签序列不出现在top-k结果的情况的惩罚力度,当标签序列出现在top-k结果中时,这项的数据为0
6.2 Forward: Find Violations
forward其实就是指NN中的forward过程,其中主要分情况处理了标签序列是否出现在beam search top-k结果的两种情况:出现时,直接使用历史数据下的结果,不出现时(violation),使用在标签序列下的结果
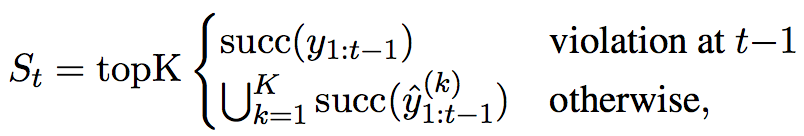
实际上,要求标签序列的score必须要以一定的margin(这里使用了1)大于beam search top-k结果中最差的(第k大)结果,即margin violation的定义为
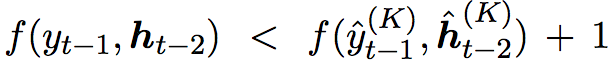
6.3 Backward: Merge Sequences
backward对应的是NN中梯度反向传播的过程,也是一个BPTT的过程,但是由于在forward过程中,输出的词语是要根据是否发生violation产生两种不同的应对方式,在BPTT中,也会通过forrward过程中记录的是否发生violation的情况来控制梯度传播的方向
两个过程的算法如下所示

7. 实验结果
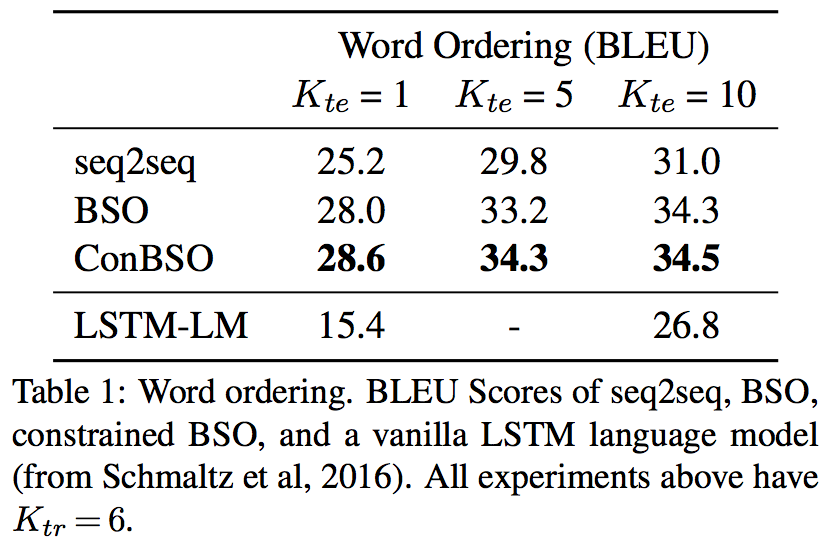
7.1 Word ordering
把一个序列shuffle后的结果当作输入序列,原始的序列当作输出序列
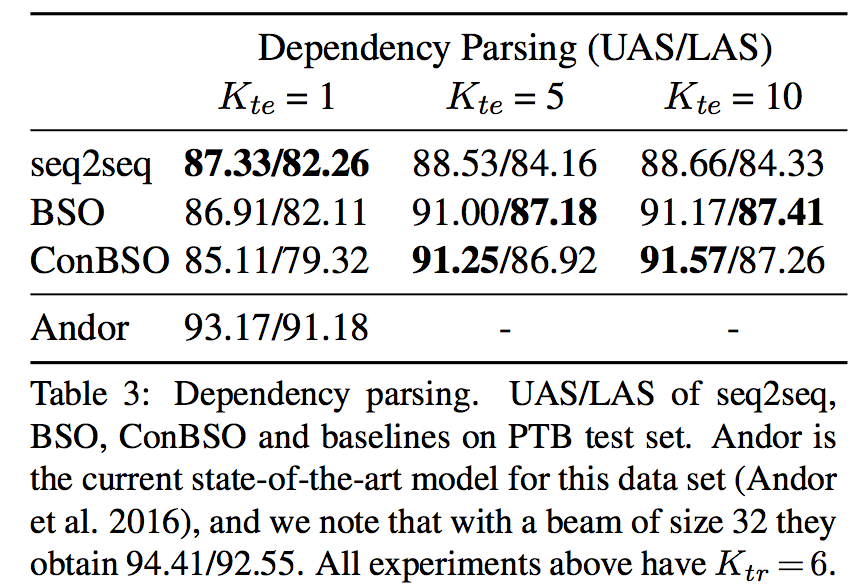
7.2 Dependency parsing
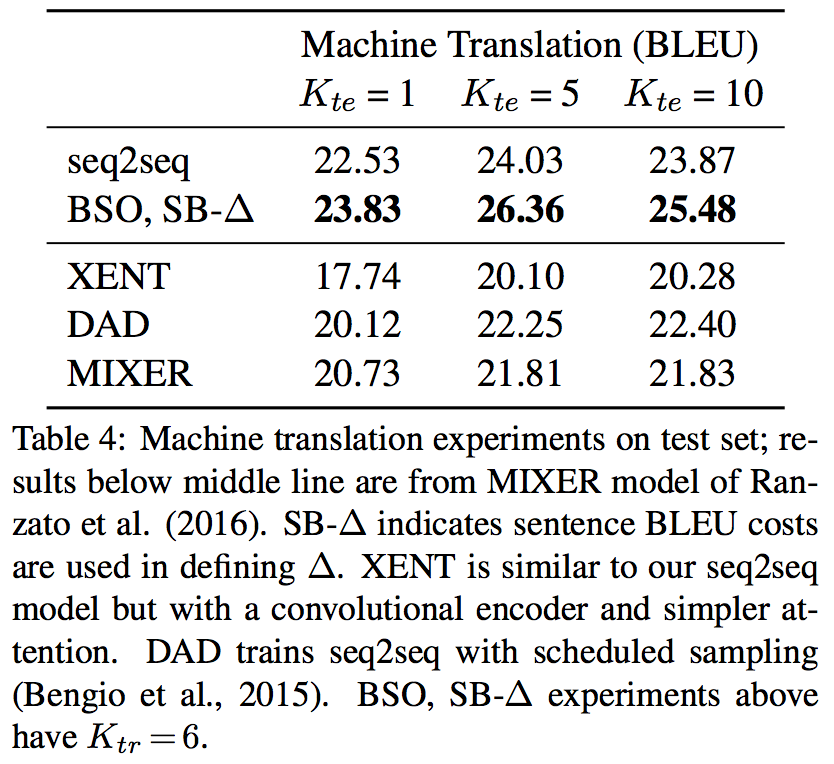
7.3 Translation
8. 个人总结
这篇文章的主要目的是解决传统seq2seq训练过程中的一些问题,如exposure bias,loss-evalution mismatch,label bias。对于exposure bias,我觉得这种bias很类似于imitation learning中的distribution drift,训练过程中一直使用的是label data,但是在测试过程中由于误差,在序列的生成过程中,分布已经偏离了训练时label data的分布,这样会造成最后的结果不理想。本文中通过在beam search中监测violation并做相应处理的方式,实际上是允许在训练的过程中,根据历史数据输出来产生词语!这个过程使得在训练过程中和测试过程中的处理方式是有一定相似性的了!因此一定程度上减少了之前提到的exposure bias问题。
-
前一篇
Reinforcement learning introduction -
后一篇
Variational Reasoning for Question Answering with Knowledge Graph