1. 来源
ICLR 2017
2. 作者信息

3. 概要
通常的机器阅读模型使用uni-directional attention机制来对聚焦部分的文章(这里文章即对应原文中的context)文本。本文提出了Bi-Directional Attention Flow(BiDAF)模型,模型在不同粒度上对文章进行表示,并且使用了Bi-directional attention flow来获得文章的表示。本文在SQuAD和CNN/DialyMail Cloze test上进行实验,并取得了很好的结果
4. 模型
BiDAF如下图所示
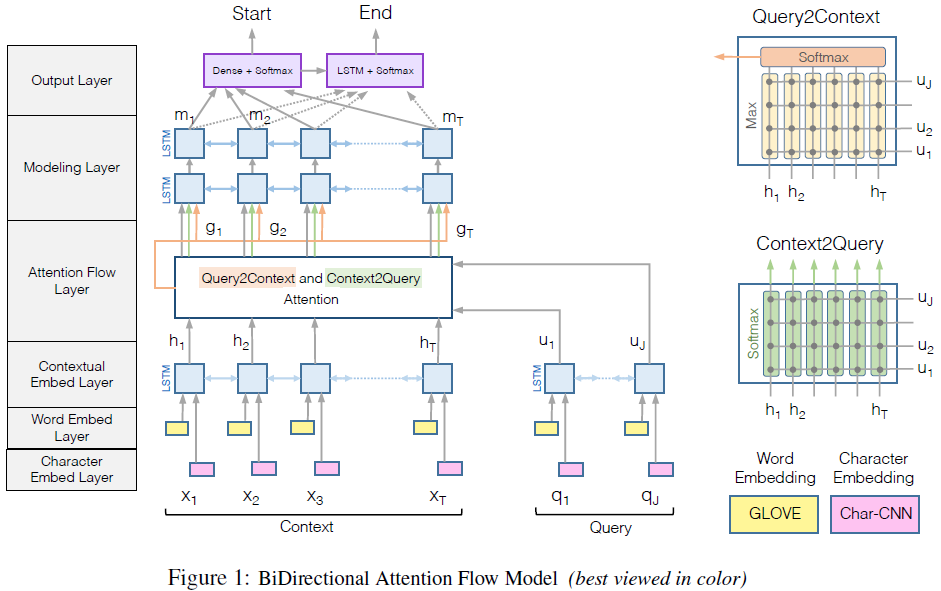
其中包含6层
4.1 Character embedding layer
Character embedding layer将每个word映射为向量。使用CNN(Kim(2014))来进行character-level embedding,对于word中的每个character,将其编码为向量,之后使用CNN对character序列处理,然后通过max pooling得到每个word定长的向量
4.2 Word embedding Layer
使用了GloVe来得到每个word对应的embedding向量。
Chracter embedding向量和word embedding向量的连接使用两层的highway network处理。
4.3 Contextual Embedding Layer
对之前层的输出,使用BiLSTM进行处理
到目前为止的3种embedding layer对文章和问题分别进行处理(对应的结果分别为H和U),并捕捉得到它们在不同粒度下的表示,这点类似于CNN中mlti-stage特征的计算
4.4 Attention flow layer
对文章和问题中的信息进行连接和混合。和之前常见的attention机制不同,attention flow layer并不是将问题和问题转化为一个特征向量。在每个时刻,通过attention得到的attention向量和之前的embedding层的结果一起,flow到之后的层中
在attention flow layer中,通过两种方向计算attention:文章对问题的attention以及问题对文章的attention,这两种attention,都由同一个相似矩阵得到
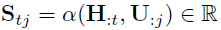
相似度计算的公式为
其中 $ w_{(s)}^T $ 为参数
-
Context-to-query attention
Context-to-query attention(C2Q)计算文章中的每个word对于问题的attention,这个过程是一个典型的attention机制的使用过程
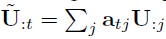
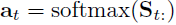
-
Query-to-context attention
Query-to-context attention(Q2C)计算得到和问题中每个word最相关的文章中的word
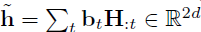
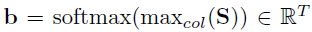
两种attention的结果最后组合得到G
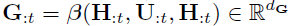
其中
4.5 Modeling Layer
Modeling layer使用BiLSTM得到在问题下的文章的表示之间的交互关系,这和contextual embedding layer不同,contextual embedding layer使用BiLSTM得到文章的表示之间的交互关系,并不包含问题的信息
4.6 Output Layer
预测得到答案的开始和结束位置,开始位置和结束位置在文章上的概率分布为
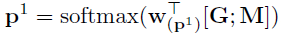
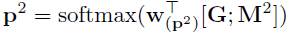
其中M是Modeling layer的输出,而 $ M^2 $ 是M通过一个BiLSTM得到
- 训练
目标函数是最大似然函数
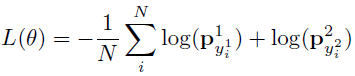
- 测试
选择答案区间(k,l)以满足最大化
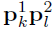
5. 实验
5.1 QA实验
在SQuAD上进行实验,结果如下
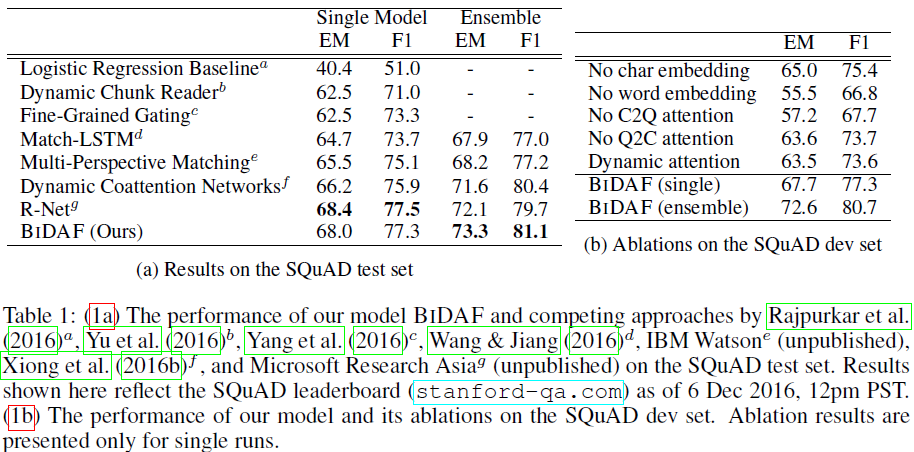
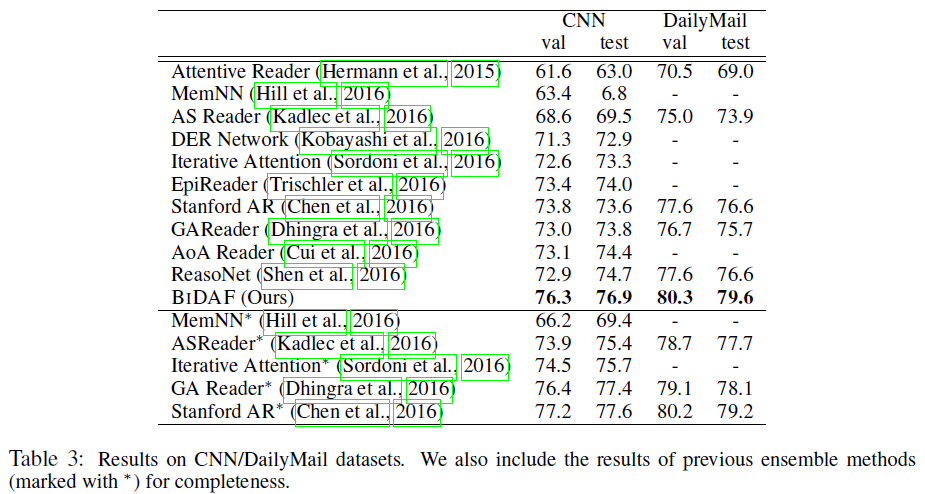
5.2 Cloze Test实验
由于Cloze Test中答案的长度为1,在原始的模型上,对output layer进行了修改,省略了中止位置
使用了CNN/DailyMail Cloze Test数据集,结果如下