1. 来源
CVPR 2016
2. 作者信息
Joseph Redmon⇤, Santosh Divvala⇤†, Ross Girshick¶, Ali Farhadi⇤† University of Washington⇤, Allen Institute for AI†, Facebook AI Research¶ http://pjreddie.com/yolo/
3. 概要
本文提出了一种统一的目标检测模型,YOLO。模型中使用一个神经网络处理输入的图片,并预测得到bounding box和对应的类别概率,由于整个模型中使用了一个神经网络,整个模型可以进行端到端的优化。
模型的速度非常快,能够实时处理图片(45 fps),一个使用更小的神经网络的模型,Fast YOLO,能够达到155fps的处理速度
4. 介绍
R-CNN等基于region proposal的方法通常包含以下步骤:首先从图片中产生候选区域,然后对候选区域进行分类,最后对候选区域进行修正。这种复杂的流水线过程速度很慢,并且由于每个部分都是单独训练,因此很难进行优化。
而在本文提出的模型YOLO中,目标检测问题被看作一个统一的回归问题,直接从图像输入到bounding box以及对应的类别概率。
YOLO的过程非常简单,如下图所示
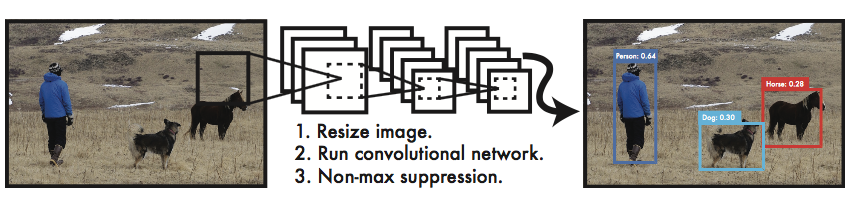
从图中可见,其过程主要有3个部分
-
将图片放缩为神经网络所需的大小
-
使用神经网络对图片进行处理,得到bounding box以及类别标签
通过NMS对bounding boxes进行处理,得到最终的输出
YOLO有以下的优点
-
YOLO的速度特别快。由于在测试阶段,只需要使用卷积网络对图片处理一次,因此,速度非常快
-
YOLO利用整个图片的信息来进行预测,相比之下,基于sliding window和region proposal的方法只使用了局部的信息,因此不容易将背景识别为物体。
-
YOLO能够学习得到物体的泛化表示。当使用自然中的图片进行训练,但是用艺术图片进行测试时,YOLO的效果显著好于DPM以及R-CNN
YOLO相对于其他实时的目标检测系统来说,准确率有很大的提升,但是相比于非实时的目标检测系统,准确率还有一定的差距
5. 模型
YOLO模型如下所示
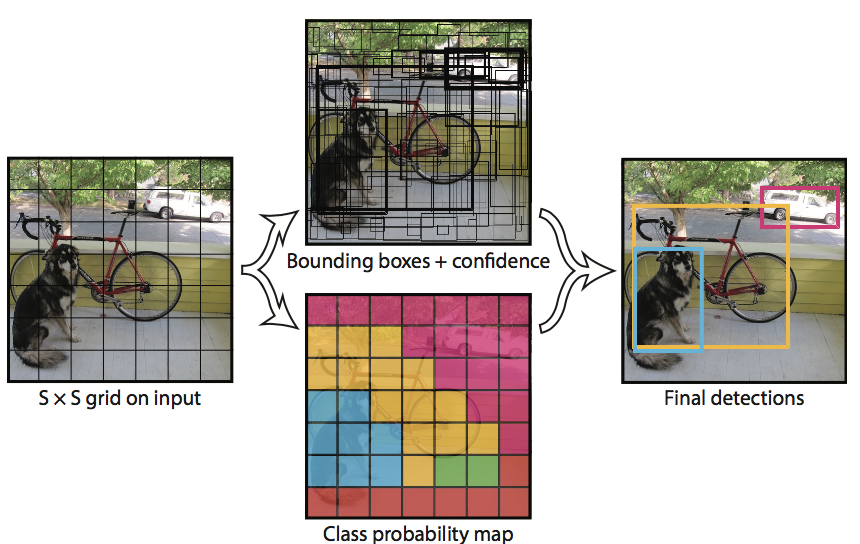
输入图片首先被分为S*S个小格,每个小格会检测中心出于改小格中的物体。每个小格会预测得到B个不同的bounding box(w,y,w,h)以及相应的置信度(confidence scores)
置信度的定义如下
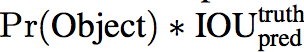
当小格中不包含任何物体时,置信度为0,否则置信度为预测得到的bounding box和实际的bounding box的IOU
此外每个小格还会预测得到C个不同类别标签的条件概率
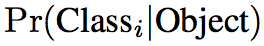
由此,可以得到每个bounding box符合各种类别标签的概率
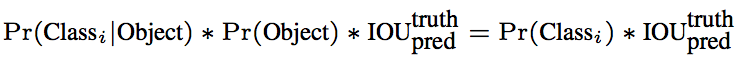
由上可知,模型的预测结果时一个SS(B*5+C)的张量
在PASCAL VOC实验中,S=7,B=2,C=20,这种情况下网络最终的输出为7730的张量
5.1 网络结构
YOLO中的检测网络是24conv + 2fc,如下图所示
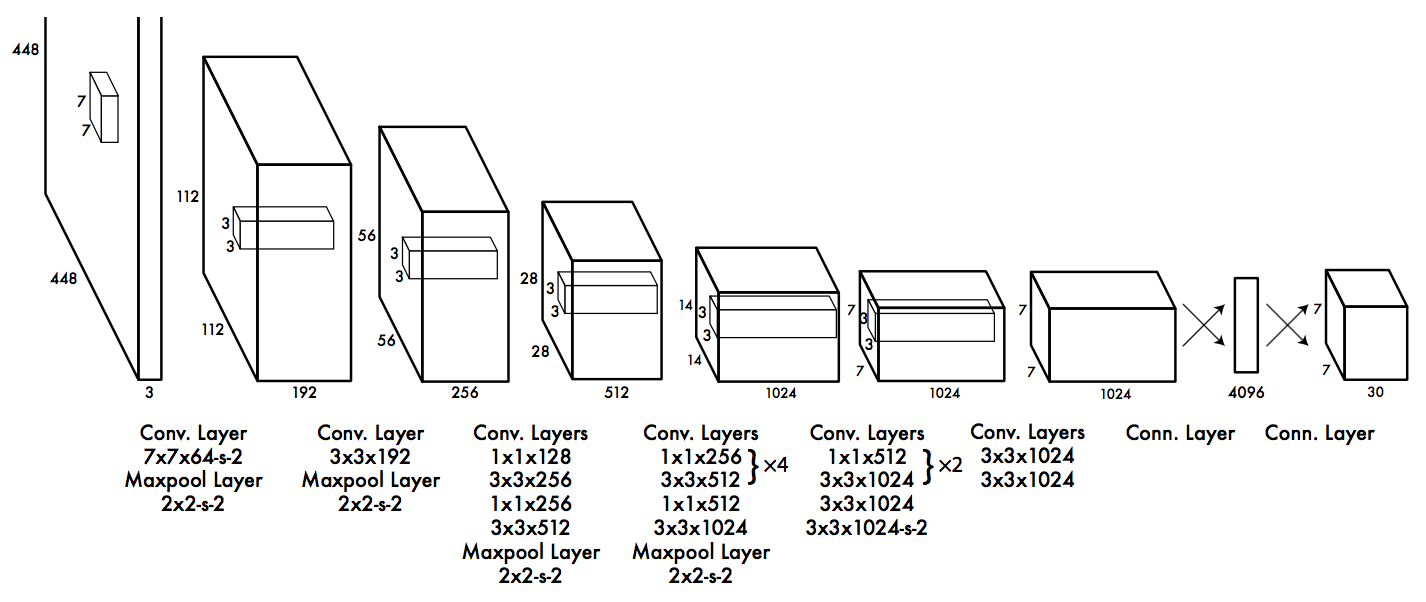
Faster YOLO和YOLO的主要区别在于网络结构,Faster YOLO使用的检测网络是9conv+2fc
5.2 训练
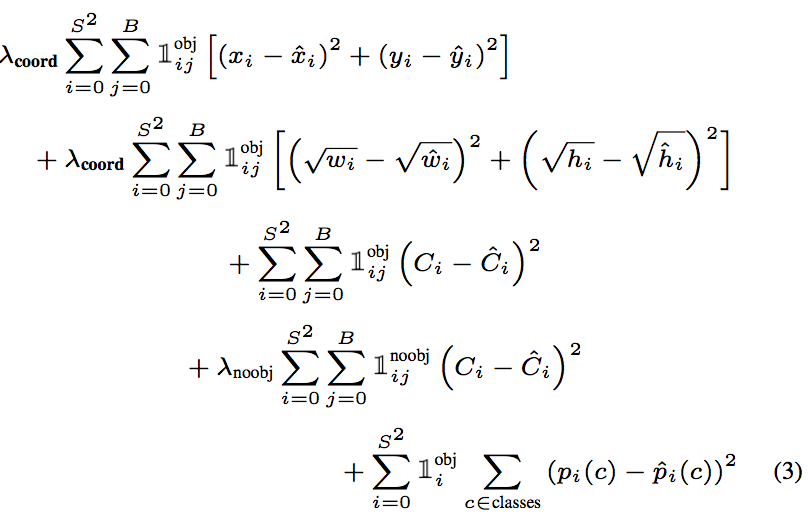
第一项表示对bounding box中心预测的损失
第二项表示对bounding box大小预测的损失,注意这里使用了根号,这是因为SSE在大的bounding box和小的bounding box下对于偏差的惩罚力度是相同的,但是模型需要让大的bounding box中的偏差受到更小的惩罚,而在小的bounding box中的偏差受到更大的惩罚
第三四项表示类别标签预测的惩罚,在小格中出现物体和小格中没有物体两种情况下,惩罚的权重是不同的
第五项表示置信度的惩罚
5.3 YOLO的局限性
YOLO有以下的局限性
-
YOLO限制每个小格只能产生B个bounding box,由此,YOLO能够检测得到的物体是有限的,因此YOLO很难处理一系列小的物体集体出现的情况
-
YOLO直接从数据中预测bounding box,因此,在遇到和训练样本差异性很高的物体时,YOLO的效果会很差
YOLO中对大的bounding box和小的bounding box的惩罚是相同的,但是通常相同的误差在大的bounding box影响较小,而在小的bounding box中影响较大
6. 实现结果
和实时模型以及非实时模型的比较
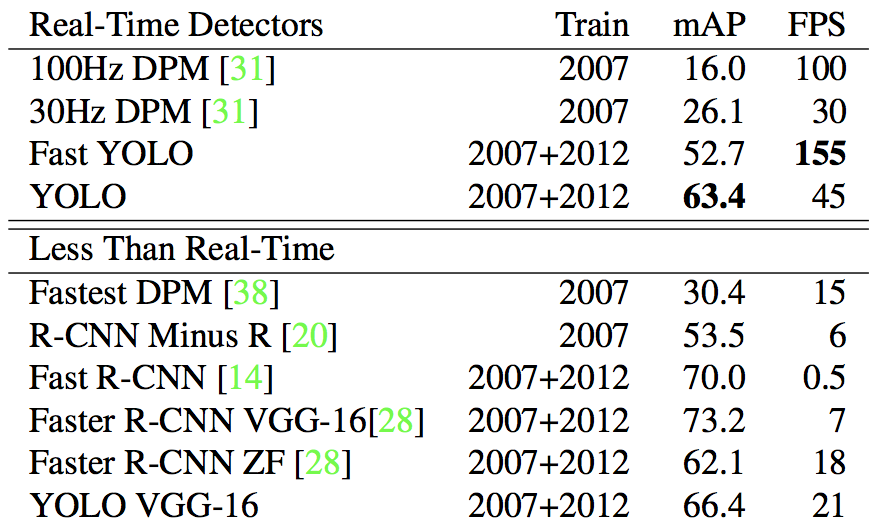
错误分析
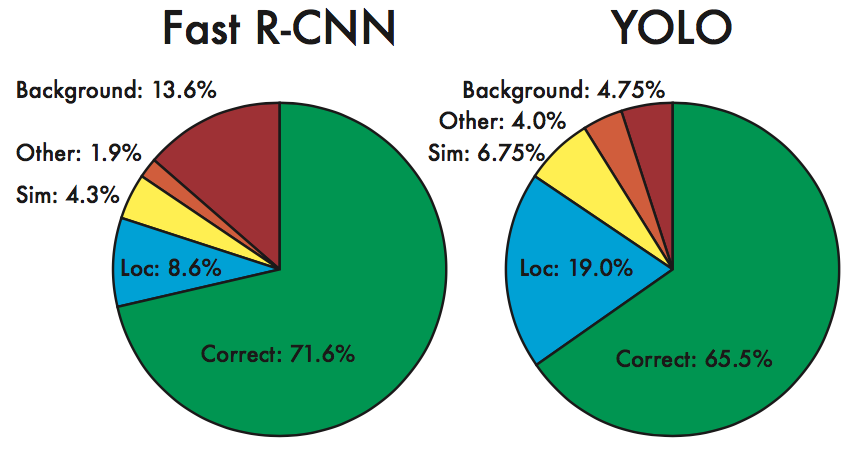
YOLO在背景上的处理效果比R-CNN方法好,因此,可以通过组合model-combination来进一步提高准确率
-
前一篇
Improved Neural Relation Detection for Knowledge Base Question Answering -
后一篇
Generative Adversarial Nets