1. 来源
ACL 2017
2. 作者信息

3. 概要
本文提出了一种通过在不同粒度对关系和问题进行文本匹配的方法来实现关系检测的模型(HR-BiLSTM)。并将这种关系检测的模型应用到KBQA中,通过实体连接和关系检测模块的互补来提高整体的准确率。在实验中,本文提出的模型能够达到很好的结果
4. 关系检测模型
关系检测模型如下所示
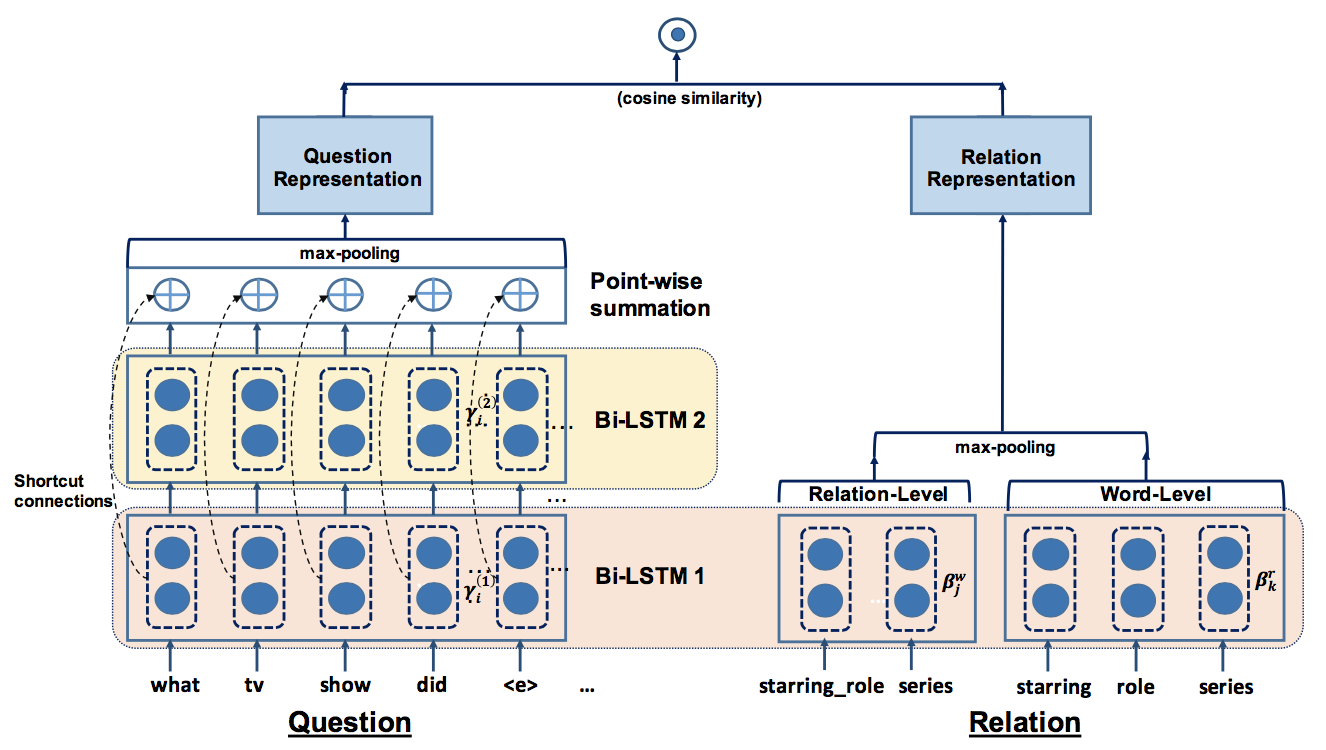
传统的关系抽取中,由于关系限定且数量不多,一般是作为文本分类进行处理,但是在KBQA系统中,由于关系的种类众多,使用传统的关系分类方法并不能很好地处理。通常在KBQA系统中的关系检测有两种思路:1.使用预训练得到的知识库中关系的embedding 2.将关系转化为一个文本序列,然后将关系检测问题看作一个文本匹配的问题。本文中沿用了第二种思路,因此首先要将问题和关系进行向量化
4.1 关系的向量表示
注意到,我们希望把关系检测的问题转化为文本匹配问题,因此首先需要解决一个问题,关系应该如何转化为一个文本序列?在之前的工作中主要有两种做法:
- 关系的文本作为一个单独token(relation-level)
这种做法的缺点在于token的稀疏性,因此难以适用于大规模的开放域关系检测
- 关系的文本作为词序列(word-level)
这种做法能够更好地泛化,但是由于没有使用完整的关系文本,也丢失了一定的全局信息
两种做法的实际处理情况如下图所示

从图中可见,word-level着重于局部信息(词以及短语),而relation-level着重于全局信息(文本的长片段)但是会有数据稀疏的问题
为了利用关系在不同粒度上的信息,本文提出的模型中中同时使用了关系在relation-level和word-level的表示。方法也很简单,使用两个不同的Bi-LSTM对关系relation-level序列和word-level序列进行处理,得到隐藏层表示,然后分别对隐藏层进行最大池化操作得到每种粒度的表示,最后将其拼接起来。整个过程如上图中右半部分所示
4.2 问题的向量表示
在得到问题的向量表示的过程中,也希望能够得到不同粒度的表示。模型中使用了多层 BiLSTM来达到这个目的。不同层次的BiLSTM的输出包含了不从粒度的表示。在得到不同粒度的表示后,如何混合这些不同粒度的信息的方法也很简单,模型中直接使用了point-wise summation。整个过程如上图中左半部分所示
4.3 训练
目标函数为
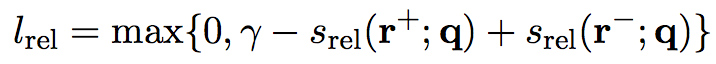
5. 使用关系检测模型提高KBQA准确率
通常的KBQA会在实体连接后进行关系检测,但是实际上关系检测的结果可以用来对实体连接的结果进行修正(re-ranking)。基于这个思路,本文提出了以下算法

算法中,re-ranking的计算如下所示
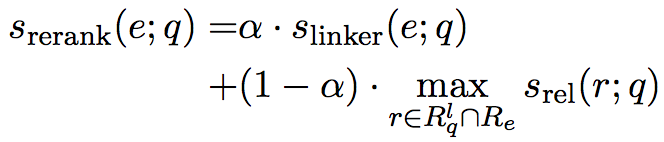
query generation的计算如下所示
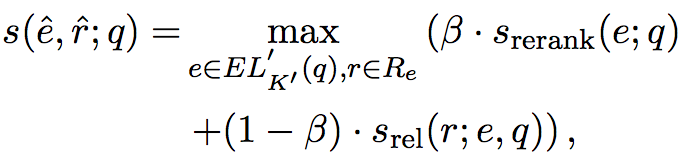
6. 实验结果
- 关系检测
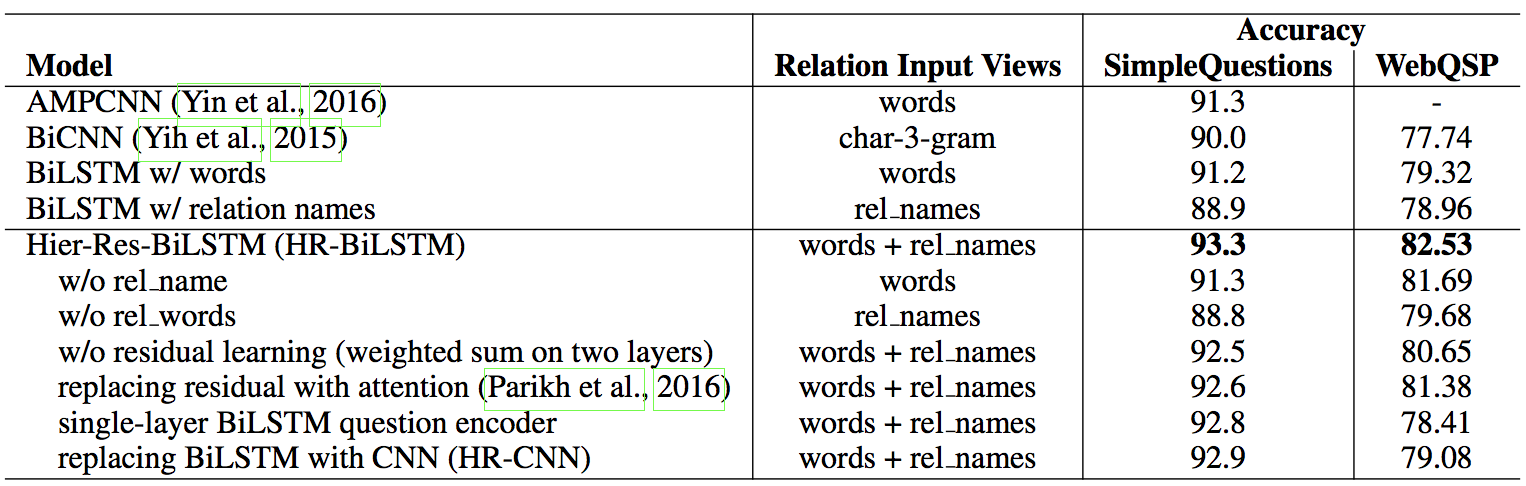
- KBQA
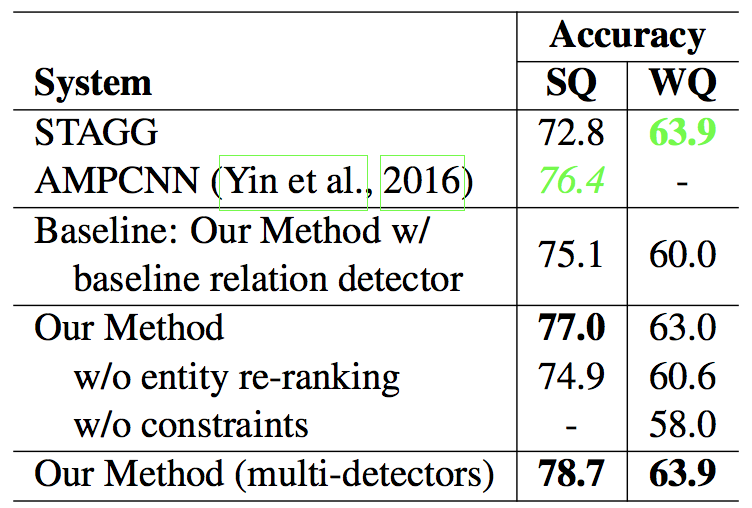
7. 个人总结
这篇文章通过将关系检测的问题转化为文本匹配问题进行解决,并通过一方面对关系进行relation-level和word-level的处理,另一方面对问题进行不同程度的表示来实现文本的多粒度表示,但和之前接触的文本匹配问题有所不同,本文在文本匹配中并没有在不同粒度上进行匹配,而是对于问题和关系,单独地将不同粒度的表示进行融合,融合的方式很简单,但是实验结果中的效果还是很显著的
-
前一篇
Semi-Supervised QA with Generative Domain-Adaptive Nets -
后一篇
You Only Look Once: Unified, Real-Time Object Detection