1. 作者信息
Zhilin Yang Junjie Hu Ruslan Salakhutdinov William W. Cohen School of Computer Science Carnegie Mellon University {zhiliny,junjieh,rsalakhu,wcohen}@cs.cmu.edu
2. 来源
ACL 2017
3. 概要
本文提出了GDAN(generative Domain-Adaptive Nets)以在QA任务中利用无标签的数据来增强QA的效果。GDAN是一个典型的GAN结构,其中包含了生成模型和判定模型,生成模型从未标注的文本中产生问题,这些问题和标注的问题一起被判定模型(也就是最终训练得到的QA模型)处理。实验中,GDAN相比于baseline模型(本文提出的一个模型),有不错的提升。
4. 模型
GDAN模型包含两个模型:生成模型以及判定模型
• 判定模型(也就是最终训练得到的QA模型)
判定模型的输入包括问题q,段落p以及一个domain_tag(添加在q和p的末尾,表示问题文本对的来源,模型生成/人工标注),输出是文本中答案的开始和结束的位置
判别模型使用了gated-attention(GA)reader((Dhingra et al., 2016) )作为基本结构。问题q和段落p先使用embedding+BiGRU得到对应的表示H_p 和H_q,然后通过gated-attention机制,对段落中的每个词p_i,计算
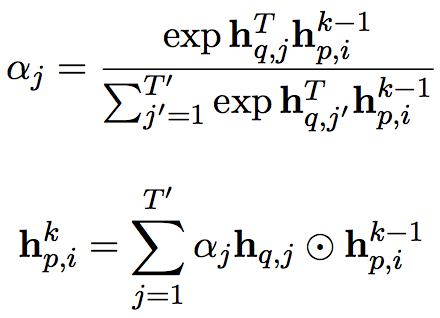
最后通过两个softmax层分别预测答案的开始和结束位置
• 生成模型
生成模型的输入包括段落p(答案通过语义标签和规则从段落p中抽取得到,并且通过在段落p中词语的embedding 向量后添加0/1标记(表示这个词语是否出现在答案中)直接注入到段落p的表示中),输出是生成的问题q 生成模型由encoder的decoder组成
encoder是一个GRU网络,把输入的p转化为隐层向量。decoder是一个GRU+attention网络,基于encoder产生的隐藏向量生成问题q,问题中的词来自于预先定义的词表或者段落p中的词语
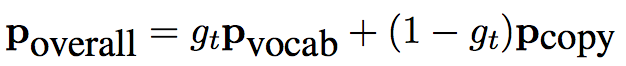
4.1 训练
训练过程如下

算法中包括3个训练过程,如下所示
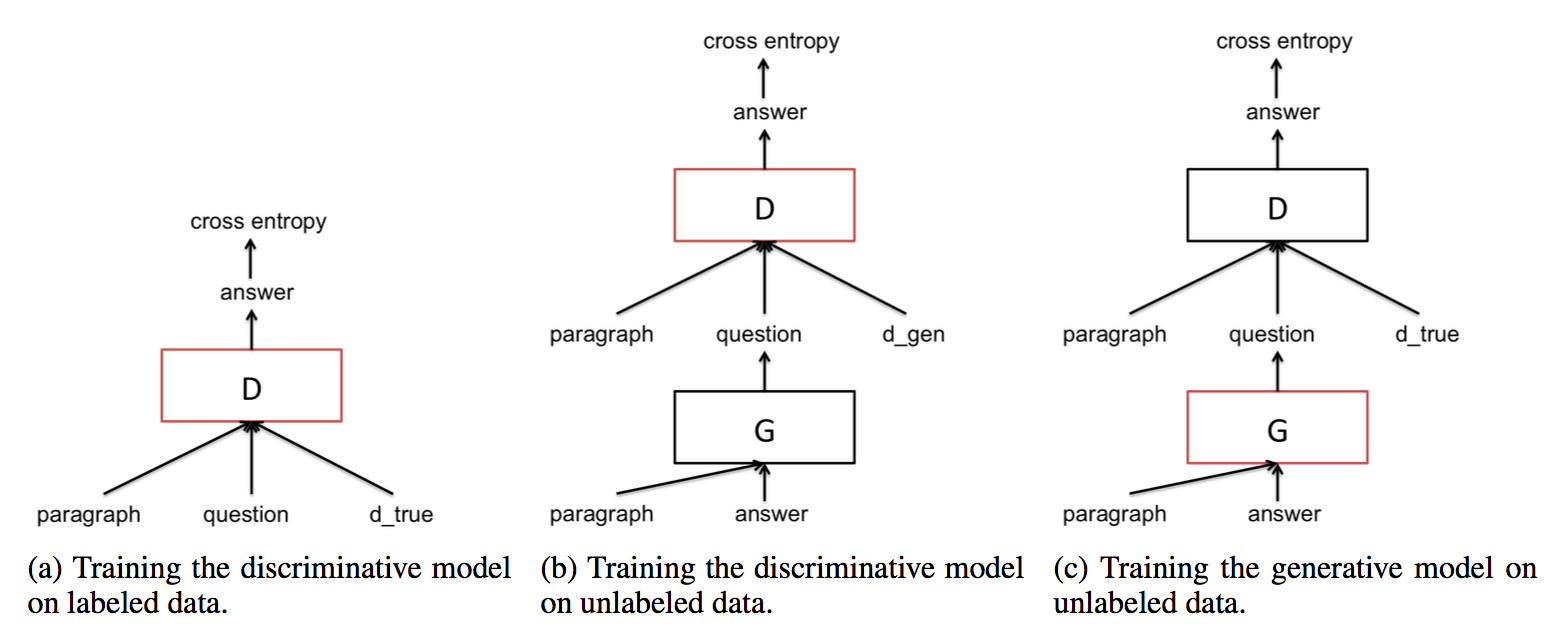
图中(a)表示预训练过程
预训练过程中,使用标注的段落问题对对判定模型进行训练,训练的目标函数是MLE
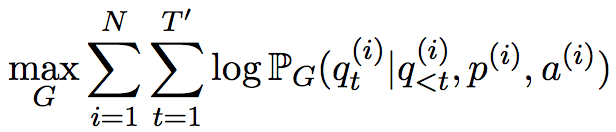
图中(b),(c)表示的是对抗训练过程中判定模型和生成模型的训练
判定模型的训练目标函数是
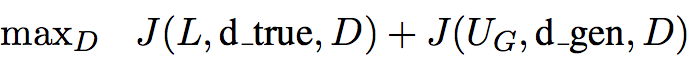
生成模型的训练目标函数是
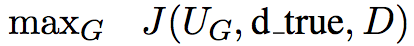
其中
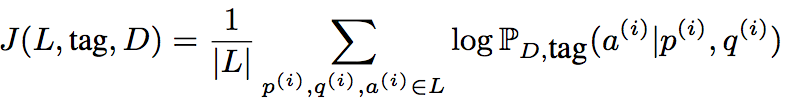
注意到生成模型产生的结果是离散,不可微的,因此使用REINFORCE算法,对应的梯度为
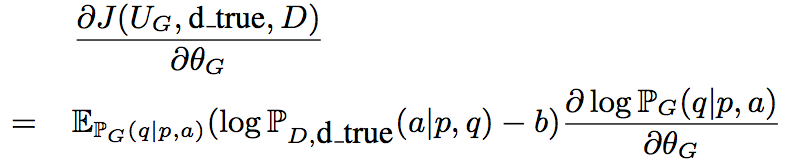
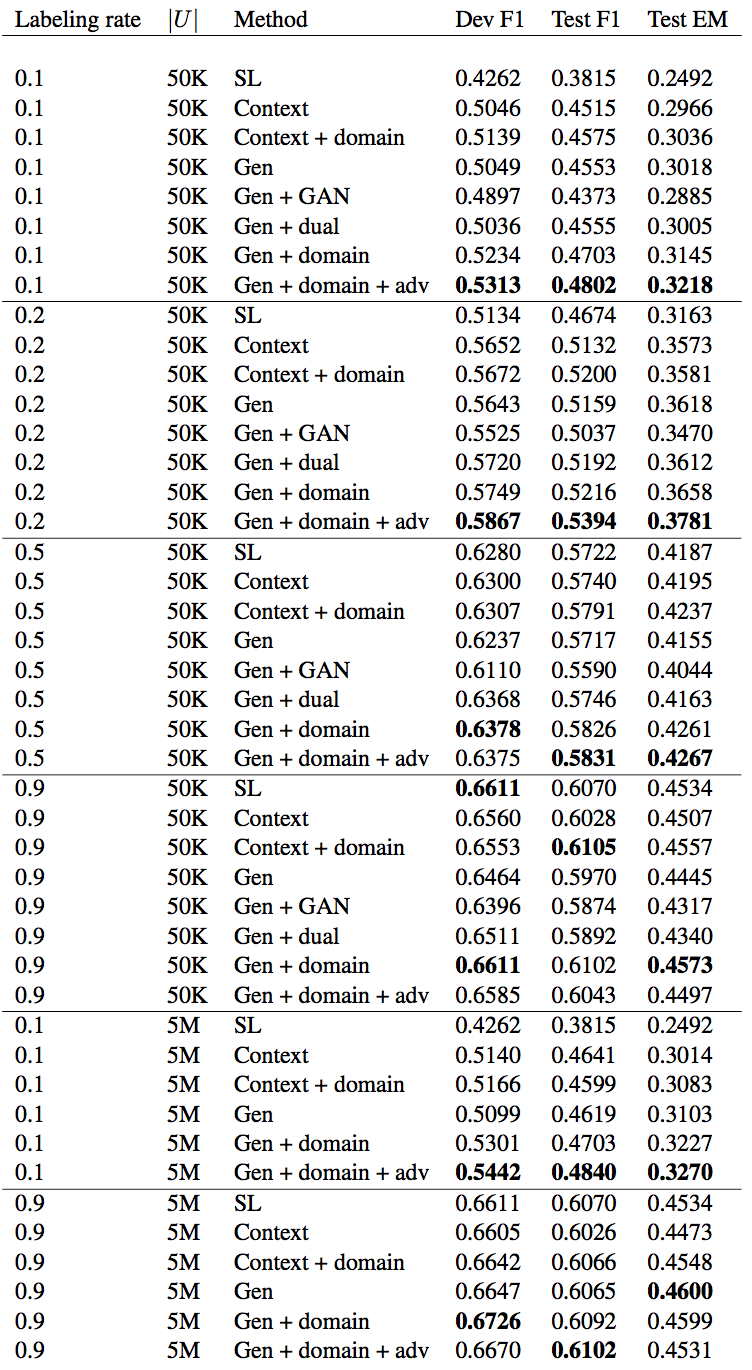
5. 实验结果
实验使用了SQuAD数据集,结果如下
6. 个人总结
这篇文章中使用了GAN的基本结构来设计了GDAN模型。由于模型中,判别网络就是最终所需要的QA模型,模型中重新设计了生成模型和判定模型的训练目标函数,比较有新意的是,在目标函数中引入了domain-tag来区分生成的样本和标签样本,这个domain-tag也是对抗过程中很重要的一个点。从结果来看,当标签数据较少时,由于能利用无标签数据,GDAN能够提升结果。
-
前一篇
Supervised learning and imitation -
后一篇
Improved Neural Relation Detection for Knowledge Base Question Answering