1. 强化学习术语及符号
强化学习的基本结构如下图所示
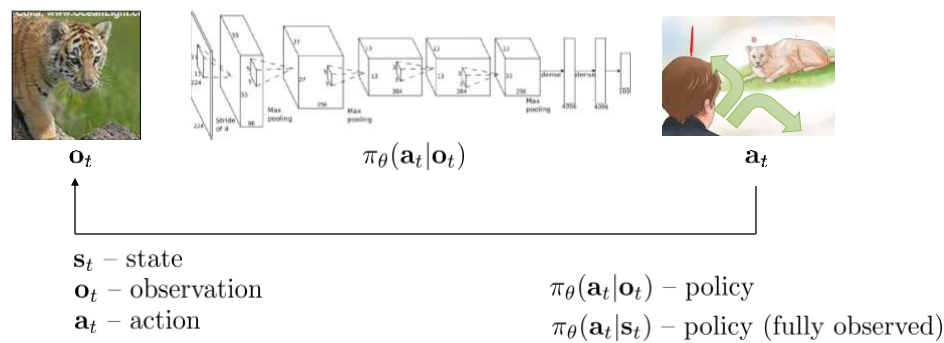
$s_t$ 表示t时刻的状态,$o_t$ 表示t时刻的观察结果,$a_t$ 表示t时刻采取的动作,$\pi_\theta (a_t |o_t)$表示策略。
通常我们假设强化学习过程是一个马可夫决策过程(MDP,Markov Decision Process)

其中$p(s_{t+1} |s_t,a_t)$是状态转移概率,新时刻的状态仅与旧时刻的状态以及旧时刻的动作有关
2. 模仿学习(imatation learning)
一种直觉的强化学习的方式是让机器模仿人类的学习。模仿学习通过人产生得到标记数据,并通过监督学习算法训练得到策略。
一个典型的例子是自动驾驶

司机在驾驶的过程中产生标记数据($o_t$ 是某时刻相机记录的图片,$a_t$ 是司机同一时刻采取的动作),通过这种方式,可以训练得到策略
但实际上,这种直觉的做法是不可行的,原因在于由于现实环境的复杂性和随机性,模型采取的动作和实际司机采取的动作不能完全相同,这个过程产生了误差,这种误差会不断地累计,导致最终模型得到的状态和实际司机驾驶得到的状态差异很大,如下图所示
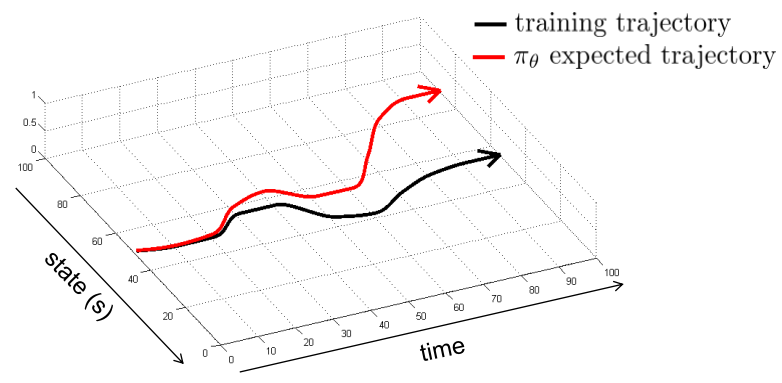
具体地讲,这是因为模型学习中使用的 $o_t$ 和实际的 $o_t$ 的概率分布不同(distribution drift),即 $p_{data} {o_t } \not= p_{\pi_\theta } {o_t }$
一种简单的想法是从 $p_{\pi_\theta } {o_t }$中获取得到训练数据,而不是 $p_{data} {o_t }$
这种想法对应的算法是Dagger
DAgger(Dataset Aggregation)

Dagger算法能够很好地解决之前提到的问题,但是其缺点在于第3步,即不断地需要人类产生地动作作为标签。
即使如此,我们也没能完美的进行模仿学习,其原因包括
- Non-Markovian behavior
人类的行为并不是一个markov process,而我们却驾驶学习得到的策略是基于MDP的,为了解决这个问题,我们可以试图使用完整的历史,一种方法是使用RNN结构
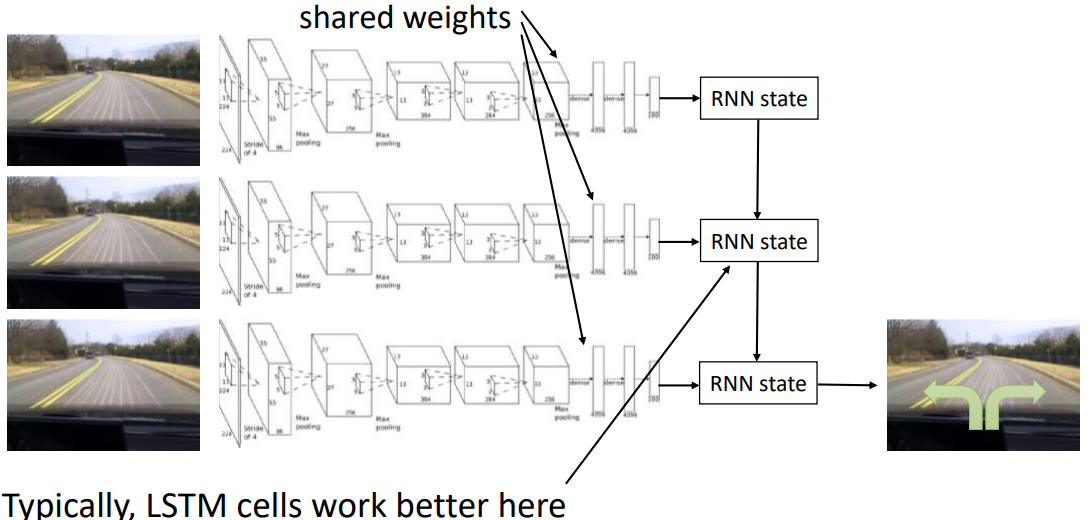
- Multimodal behavior
对应相同的状态和观测结果,输出的动作可能可以是多个不同的动作,而不是单一的一个动作,如下图

但是通常神经网络的输出是一个single-modal的概率分布,这样,往往会产生错误,如下图所示

(图中的输出结果原本应该是向左或者向右,但是fit到最终的高斯分布后,输出的结果变成了两者的平均,即向前)
a. Output mixture of Gaussians
一种最简单的方式是将神经网络的输出定义为混合高斯

但是这种方式的缺点在于,需要指定混合高斯的数量
b. Implicit density model
在网络的输入中添加一个噪音,原来网络的输出依然保持不变,为single-modal的输出结果
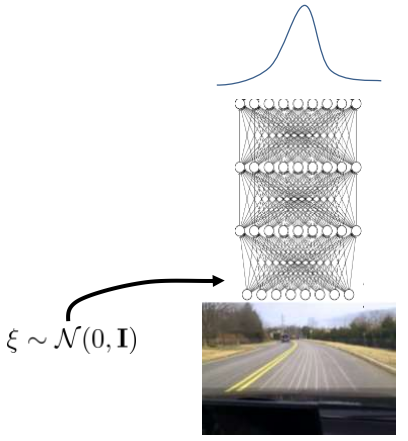
这种方式的缺点在于,难以训练
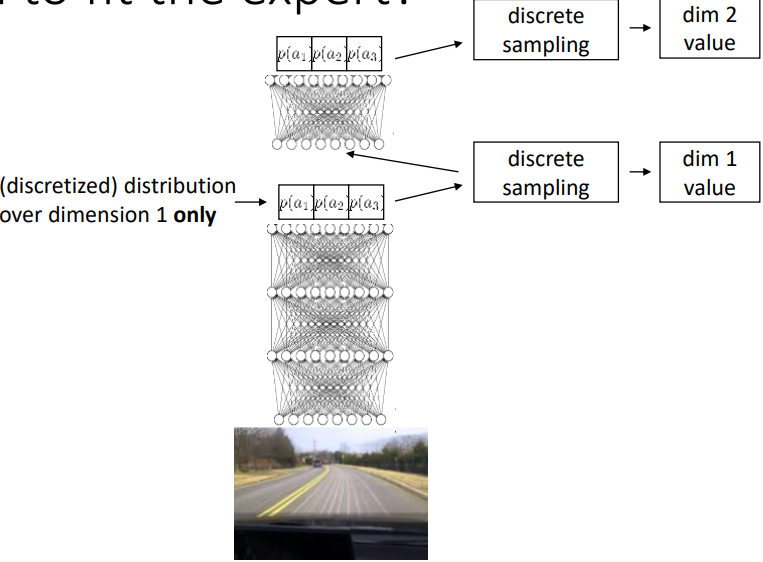
c. Autoregressive discretization
(这个还不太明白)
3. 总结
-
分布偏移问题使得模仿学习往往不能独立地良好工作
-
通过一些任务相关地方法(如驾驶中,除了正片图片,增加偏左和偏右地图片),可以解决分布偏移问题
-
可以通过添加一些on-policy数据使得模仿学习有效工作(Dagger)