1. 来源
CVPR 2015
2. 作者信息
Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik UC Berkeley {rbg,jdonahue,trevor,malik}@eecs.berkeley.edu
3. 前置内容
• IoU(Intersection of Union)
两个区域的交集和并集的比值,能够用来评估两个区域的重叠度
• NMS(Non-Maximum Suppression)
NMS的作用是抑制不是极大值的元素,搜索局部的极大值,在RCNN中,用来过滤一些boundingbox
例如对于某个类别的物体,算法就找出了一堆的boundingbox,需要判别哪些矩形框是没用的。NMS的做法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于该类别的概率分别为A、B、C、D、E、F
a. 从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
b. 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
c. 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
• selective search
selective search的主要思想是
a. 使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
b. 查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置
c. 输出所有曾经存在过的区域,所谓候选区域
其中合并的依据是
a. 颜色(颜色直方图)相近的
b. 纹理(梯度直方图)相近的
c. 合并后总面积小的: 保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域 (例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh)
合并后,总面积在新的到的boundingbox中所占比例大的: 保证合并后形状规则。
4. 概要
本文中提出RCNN(Regions with CNN feature)这种简单、可扩展的物体检测模型,并在PASCAL VOC数据集上取得了很好的结果。这种模型基于两个出发点:(1)CNN能够用来定位(localize)和分割(segment)物体,(2)当标签数据稀少时,通过辅助数据的预训练(pre-training)加上任务数据的微调(fine-tuning),能够显著提升效果
5. 模型
RCNN模型如下所示
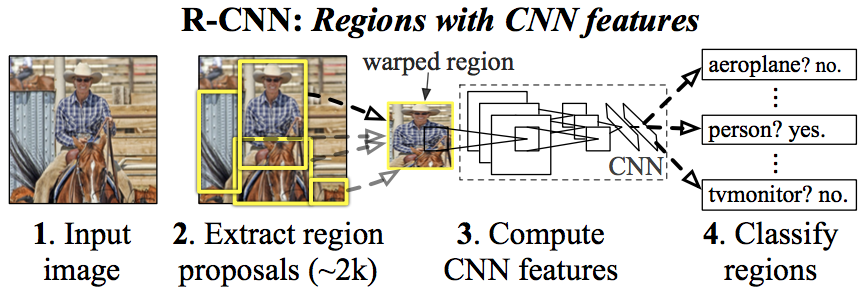
整个物体检测的模型包含3个模块
- 区域生产(region proposal)
通过算法从图片中提取得到与类别标签无关候选区域(使用对应的BB,bouding box表示,之后boundingbox和region会交替使用,但均表示原始图片中的一块区域)。区域生产算法时RCNN中独立的一部分,并不会影响到后续的部分,RCNN中使用了selective search区域生成算法(Uijlings e.l,2013)
- CNN特征提取
CNN网络的输入是227*227的RGB图片,RCNN中使用的是CNN产生的4096维的特征向量(文中对比了使用不同层的特征向量对结果的影响)。
RCNN中可以使用不同的CNN模型,实验中使用了AlexNet(T-Net)和VGG-16(O-Net)
在将产生的区域输入到CNN前,首先需要将区域图片转化为CNN输入对应的227*227的图片大小,文中提出了以下几种方式
a. 各向同性缩放
- tightest square with context
先将区域扩充到最小的方形区域(tightest square),扩充的区域直接使用原始图片中的内容,如果超出图片边界,则填充区域中颜色的均值,然后再将得到的方形区域缩放到CNN需要的输入大小
- tightest square without context
先将区域扩充到最小的方形区域,扩充的区域填充区域中颜色的均值,然后再将得到的方形区域放缩到CNN需要的输入大小
b. 各向异性缩放
区域的长宽方向进行不同比例的放缩,得到CNN需要的输入大小
在预处理的过程中,先在原始的区域周围进行padding能够有效地提高模型的结果,RCNN中使用的padding大小为16像素
以上的区域处理方式的效果如下图所示

其中A列表示原始的区域,B列表示tightest square with context,C列表示tightest square without context,D列表示各向异性缩放,1、3行表示padding为0的结果,2、4行表示padding为16的结果
- 针对不同类别标签的SVM分类器
对于所有的物体种类标签,相应的SVM分类器(二分类)对其进行分类
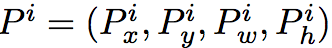
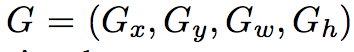
RCNN中假设位置的改变通过平移操作,而大小的改变通过log空间的放缩操作
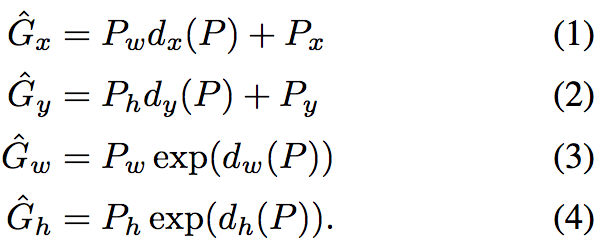
其中表示回归模型的结果
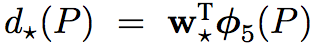
对于4个回归值,单独进行回归,误差函数为
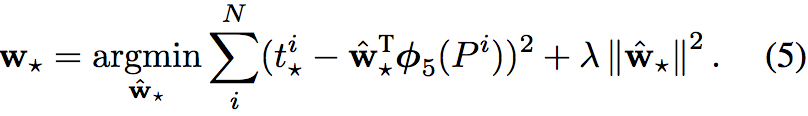
回归目标定义为
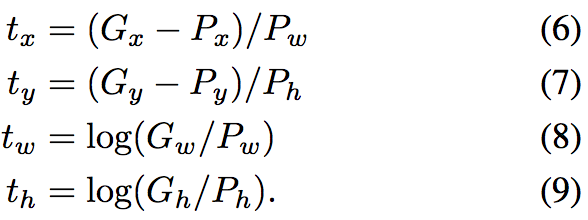
在回归模型中,需要注意到两个问题
-
正则化约束很重要,RCNN中使用了λ=10000⁆,较大的正则项保证对boundingboxde的修正不会太大
-
训练中使用的数据(P, G)应该是接近的,具体的对于一个G可以选择和它IoU最接近的,且IoU>0.6的P
5.1 测试(testing)
测试过程中,首先通过selective search(fast mode)从图片中提取得到2000个左右的候选区域(region proposal),对区域进行处理后将候选区域通过CNN处理的到对应的特征。对于每种类别标签,使用相应的训练好的SVM计算相应的分数,进而得到区域对应不同标签的分数,最后通过贪心的NMS(对于每个类别)删除部分的区域 测试过程中RCNN的速度相比于之前的模型还是很快的(13s/image on a GPU or 53s/image on a CPU ),这得益于以下两点
-
所有候选区域都使用同一个CNN进行处理
-
CNN处理的到的特征的维度相比于之前的模型要低
5.2 训练(training)
RCNN模型的训练过程分为多个步骤
• 有监督的预训练(pre-training)
CNN模型在ILSVRC2012 classification任务上进行预训练
• 针对指定数据(domain-specific)的微调(fine-tuning)
首先将CNN最后的针对ImageNet的1000类分类器改成任务相关的N+1类分类器(N是任务的分类数,加上额外的一个类别表示背景),和真实的区域(region)的IoU大于0.5的区域为正样本,其余的区域是负样本,通过SGD进行训练,每个batch的大小为128,其中有32个正样本和96个负样本(由于整体样本中,正样本的数量远小于负样本,通过这种方式,可以向正样本倾斜)
• 目标分类(object category classifiers)
对于每个类别,单独训练SVM进行二分类。所有包含真实的区域的区域被作为正样本,而和真实区域的IoU<0.3(grid search得到)的区域作为负样本,其他的区域不使用
注意到在fine-tuning和classify的过程中对于正负样本的定义方式是不同的,并且RCNN中重新训练了SVM分类器,而没有直接使用fine-tuning后CNN的softmax。
这是由于cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IoU只要大于0.5都被标注为正样本了);然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm
6. 实验结果
-
PASCAL VOC 2010-12 上的结果
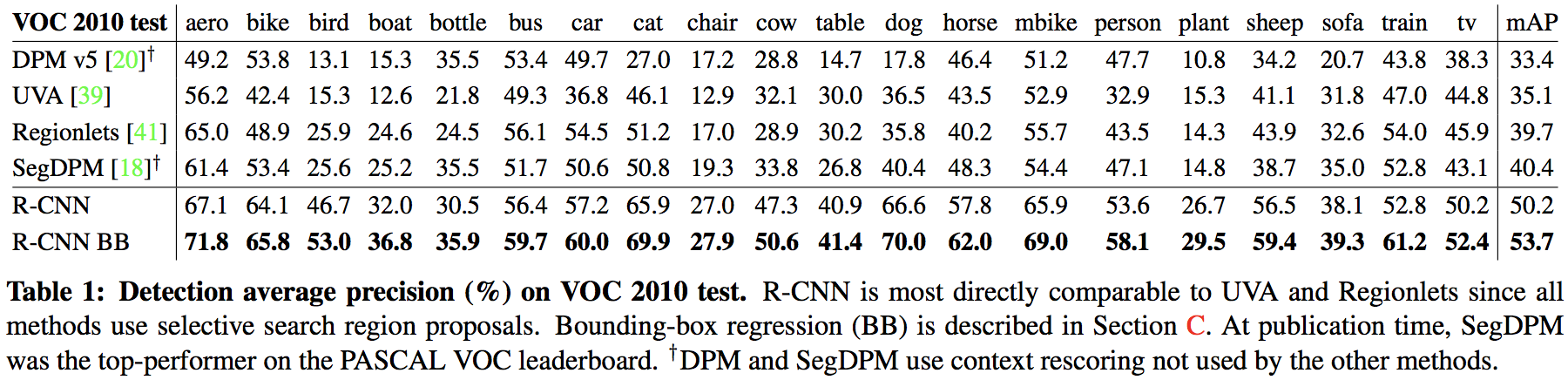
-
使用CNN不同层的输出作为CNN特征
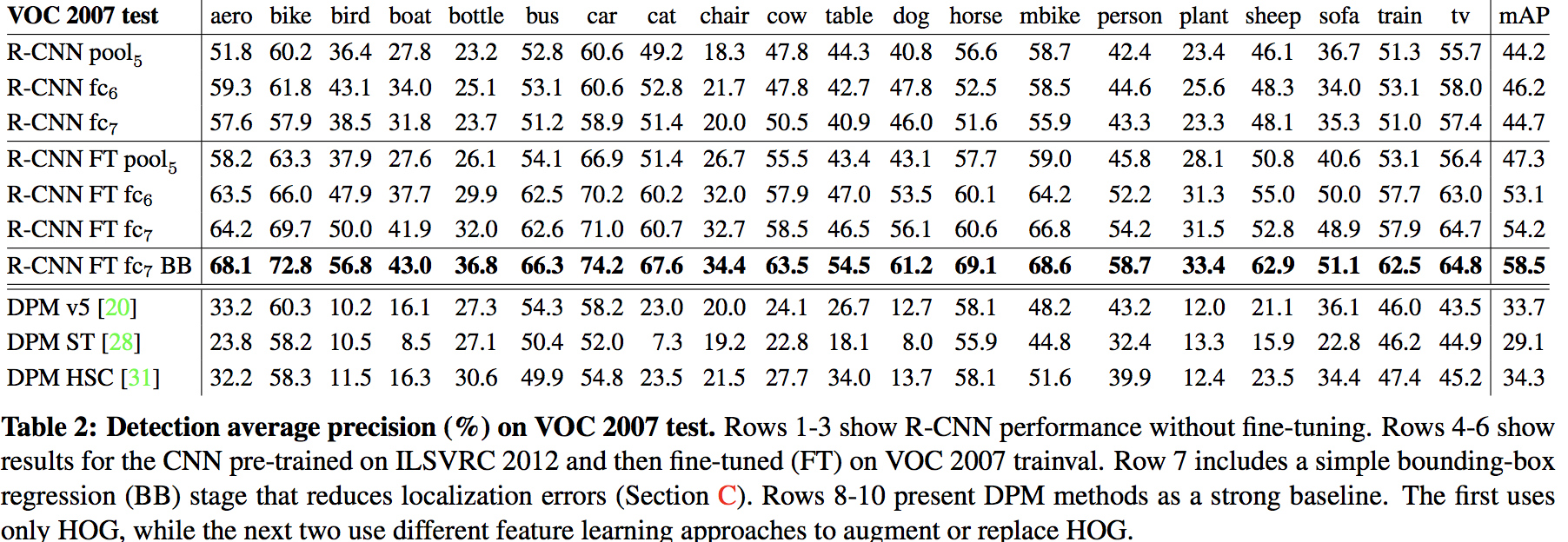
-
网络模型结构的影响

-
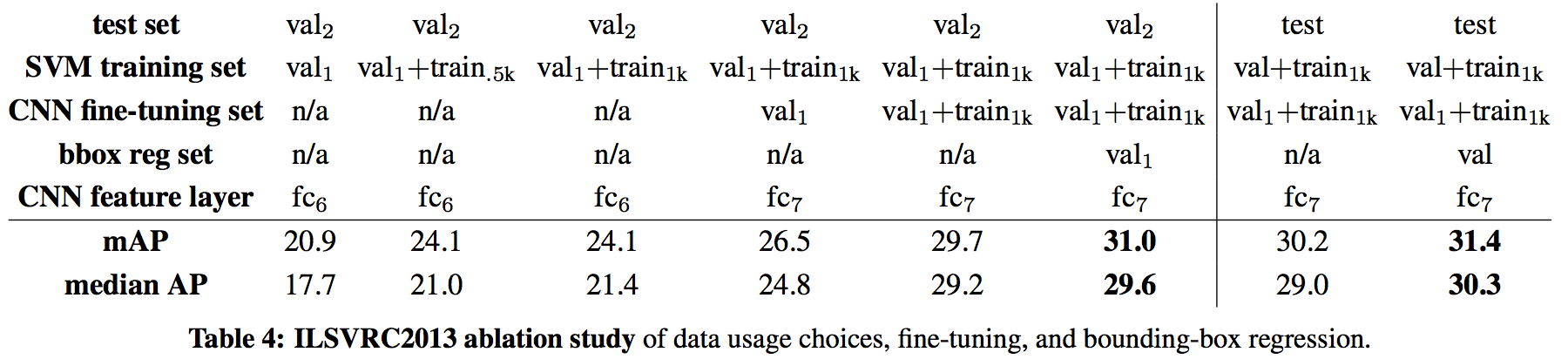
Ablation 实验