1. 来源
ICLR 2018 under review
2. 作者信息
Guillaume Lample * † , Ludovic Denoyer † , Marc’Aurelio Ranzato * * Facebook AI Research, † Sorbonne Universite ́s, UPMC Univ Paris 06, LIP6 UMR 7606, CNRS {gl,ranzato}@fb.com,ludovic.denoyer@lip6.fr
3. 概要
本文提出了一种非监督的机器翻译模型,模型将不同语言预料的语句映射到相同的特征空间,并通过从特征空间的向量重构得到原始的不同语言预料的语句来训练模型。在实验中,模型能够达到不错的效果,在Multi30k-Task1 数据集上达到32.8的BLEU。
4. 介绍
机器翻译的过程可以看作是一个通过自然语句(原始语言,source language)得到相应隐藏空间向量(latent value)和通过隐藏空间向量重构(reconstruct)得到自然语言(target language)的过程。本文的主要思想是建立两种不同语言之间共享的隐藏空间(latent space),并且通过优化重构过程的LOSS来实现整个翻译模型的训练,重构的过程中遵循两个准则
-
重构过程中,** 模型能够从一个添加噪音的语句对应的隐藏空间向量中重构原始语句 **(在单语言中和DAE相同)
-
重构过程中,**模型能够从一种语言中的语句翻译得到的另一语言中的语句(添加噪音)中重构原始语句,反之亦然 **(使用back-translation得到翻译语句,即使用目前学习得到的模型进行翻译)
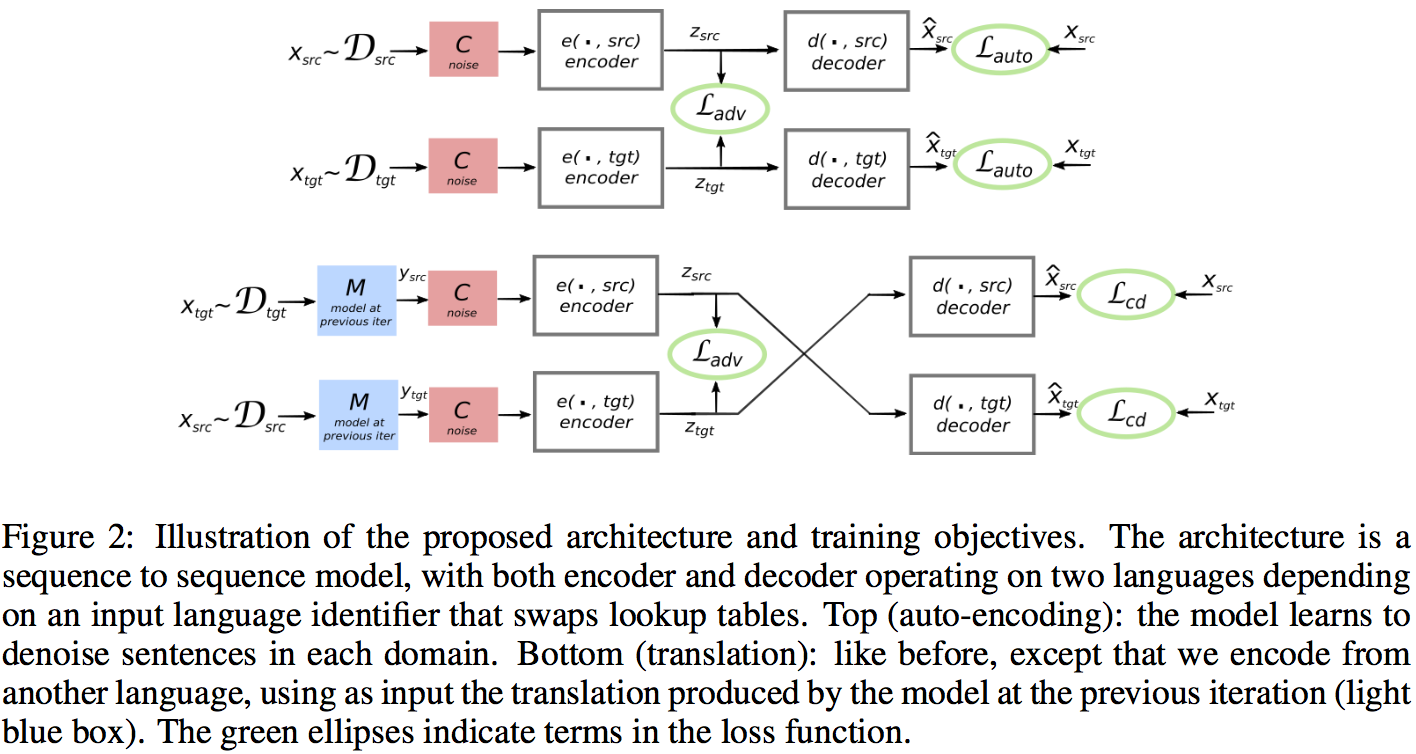
以上两个准则可以用下图表示
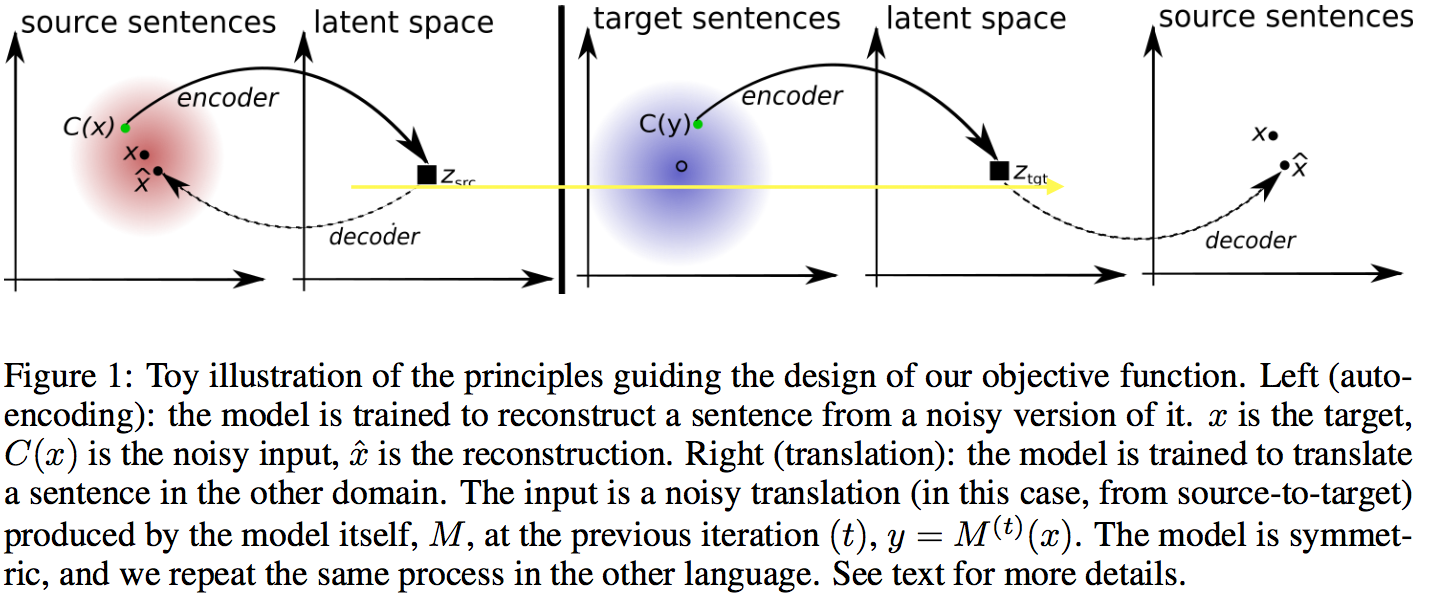
除了以上的重构目标,模型还通过对抗惩罚(adversarial regularizer)限制不同语言中的语句在隐藏空间的表示符合相同的分布:模型从不同语言中产生其在隐藏空间向量,而对抗网络同时被训练来分别隐藏空间的表示是从哪种语言中产生的。在对抗学习的过程中,模型不断地更新,翻译的质量也不断地提高。
最初始的翻译模型初始化为通过双语的词典对单语言预料进行逐字的翻译模型(word by word)(Conneau et al., 2017)
5. 模型
本文中的模型使用了s2s的模型,但是模型中对于不同的语言预料使用了同一个encoder和decoder,唯一不同的是对于不同的语言预料,使用了语言本身的lookup table(对于encoder是embedding table,decoder过程中是vocabulary)
之后用以下函数分别表示encoder和decoder
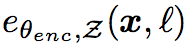
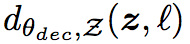
6. 目标函数
最终的目标函数比较复杂,如下所示
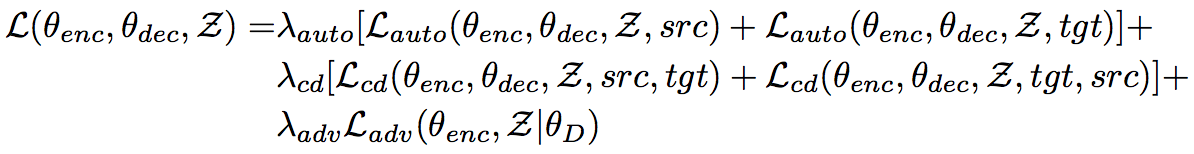
这个目标函数主要包含一下3类Loss
-
$ L_{auto} $ (Denoising AutoEncoder)
这个Loss对应着重构的第一条准则,模型能够从一个添加噪音的语句对应的隐藏空间向量中重构原始语句
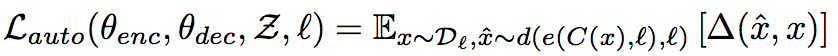
其中,x是原始的语句,$ \hat{x} $ ̂是重构数据,d是decoder,e是encoder,C是噪音函数,Δ 衡量两个句子之间的差异,这里使用了token-level的cross-entropy的和作为差异性的衡量
-
以一定的概率drop掉输入语句中的词语
-
对输入的语句进行一定的shuffle,具体的实现是对输入语句中部分相邻的词语进行交换
-
-
$ L_{cd} $ (Cross Domain training)
这个Loss对应着重构的第二条准则,重构过程中,模型能够从一种语言中的语句翻译得到的另一语言中的语句(添加噪音)中重构原始语句
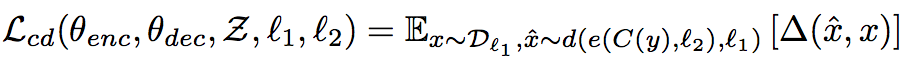
其中,y是由当前的翻译模型M翻译源语言 $ l_1 $ 中的x到目标语言$ l_2 $ 得到,即y=M(x) 可以看到,$ L_cd $ 实际上一方面鼓励不同语言的语句映射到同一隐藏空间,另一方面鼓励模型的结果语句和源语句有相同的语义,(即公式中的x,y有相同的含义,不然的话,由y重构得到的x ̂无法得到和原始x很少的误差)
-
$ L_{adv} $ (Adversarial training)
这个Loss对应着之前提到的 ‘限制不同语言中的语句在隐藏空间的表示符合相同的分布 ’这个限制
为什么要这样做呢,本文提到 在NMT系统中,decoder模块的良好效果要求其输入由和它一起训练的encoder产生,或者跟宽泛的,decoder训练时的输入需要和其工作时接受到的encoder的输出时相同的分布,因此,不管输入是何种语言,都需要将其映射到同一个隐藏空间
the decoder of a neural machine translation system works well only when its input is produced by the encoder it was trained with, or at the very least, when that input comes from a distribution very close to the one induced by its encoder
需要注意的是,仅仅有这个限制的话,decoder产生的翻译结果只是符合目标语言的语言模型,但是并不一定和源语言的输入语句相对应,但是幸运的是,之前提到的L_cd 对处理了这个问题
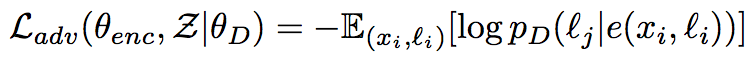
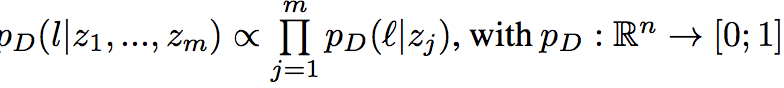
其中0表示来自于源语言,1表示来自目标语言
目标函数中的所有Loss如图所示
7. 训练
训练是一个迭代过程,算法如下所示

由于在训练期间没有监督数据,无法直接计算BLEU值,本文使用了以下的方法作为评判标准
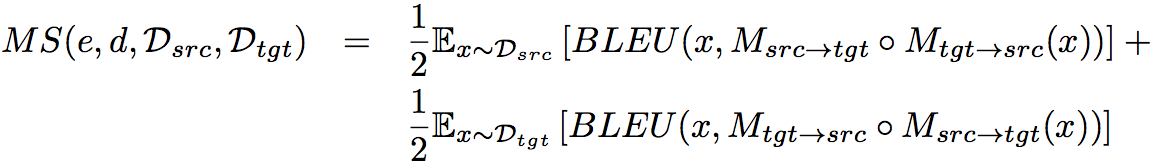
其中
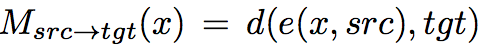
8. 实验结果
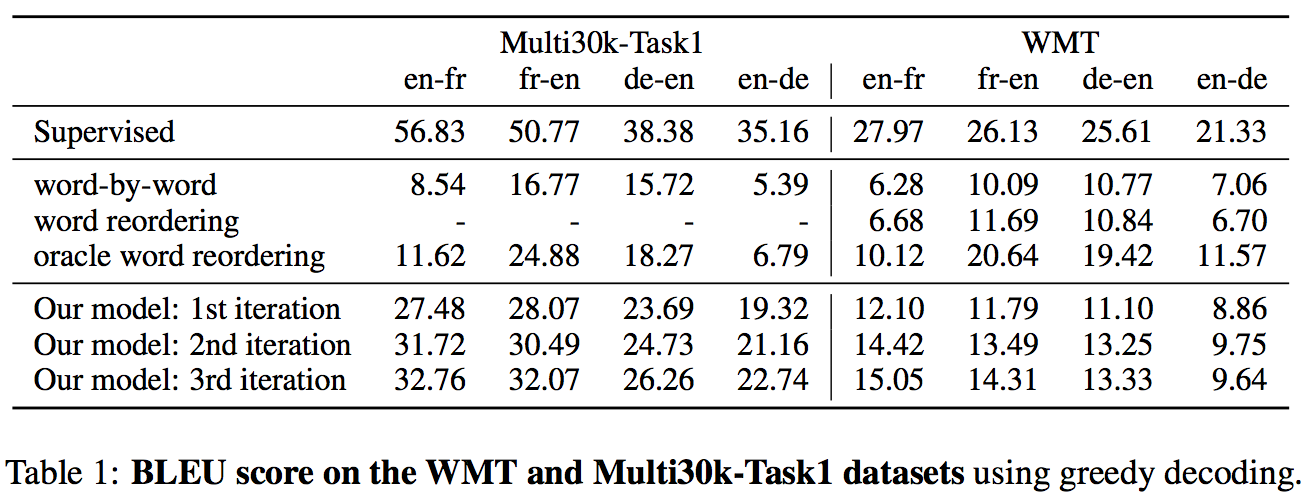
本文在WMT-14 En-Fr,WMT-16 En-Ge,Multi30k-Task1上进行了实验
- 总体情况
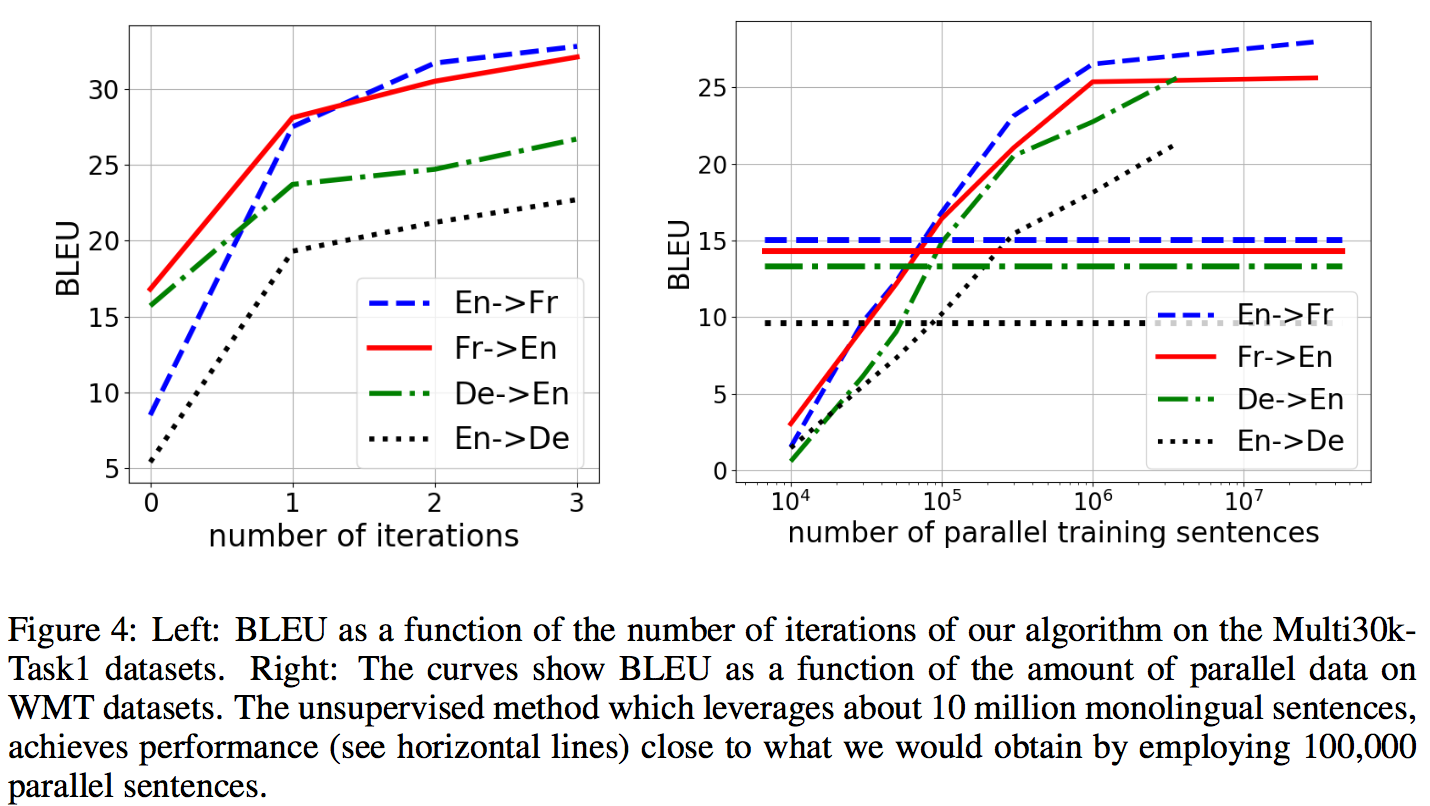
- 训练过程
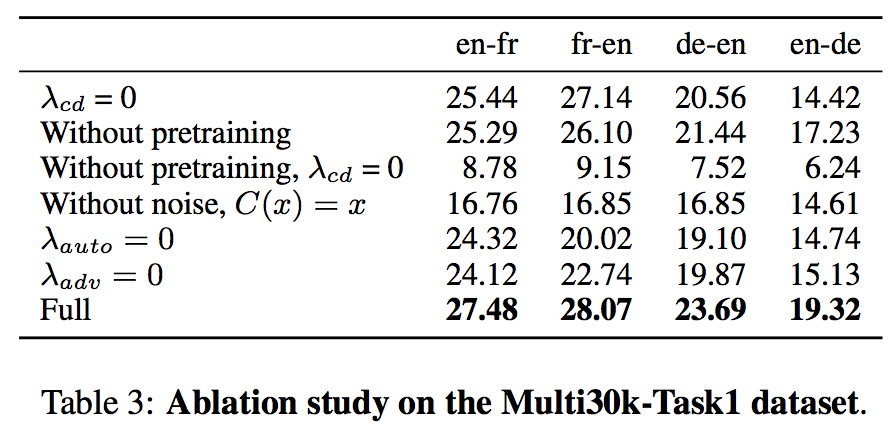
- Ablation实验
9. 个人总结
本文的想法思路是很有意思的,对不同语言使用了相同的模型进行处理,把整个MT的问题转化为不同自然语言空间->共享隐藏空间的相互转化(语言A->语言B=语言A->隐藏空间->语言B)加上两种重构损失和隐藏空间分布差异损失,因此,个人感觉整个模型的目标函数的构建是很巧妙的。
从结果看来,这篇文章的结果相对于之前的结果(《UNSUPERVISED NEURAL MACHINE TRANSLATION 》)在部分的数据集上是有进步的,但是可以看到,和有监督和半监督的模型的结果之间还有很大的差距