1. 来源
AAAI 2018
2. 作者信息

3. 概要
本文提出了一种半监督的关系抽取的方法。方法分为3个步骤:首先基于tree-GRU,在句子的语法依赖树上,获得实体的embedding,然后使用intra-sentence和inter-sentence的attention来获取得到包含目标实体对的句子的集合(bag)中每个句子的向量表示,最后使用句子的向量表示和实体的embedding来进行关系分类。在实验中,模型能够获取得到不错的效果
4. 模型
4.1 Entity embedding
Entity embedding的结构如下所示
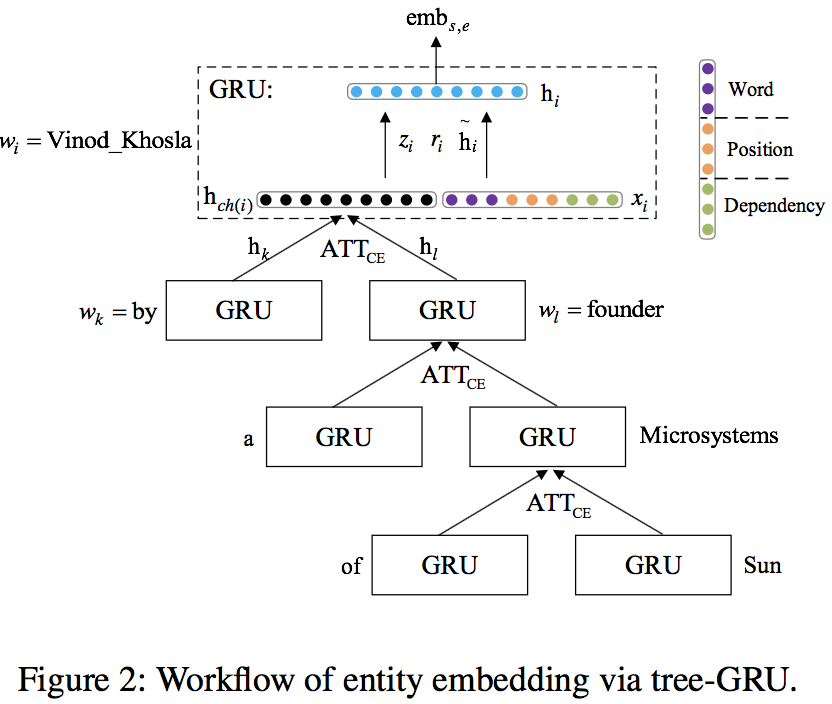
-
dependency embedding
本文使用skip-gram模型在NYT语料上训练得到word embedding。和传统方式不同的是,本文中定义上下文的方式,对应语法树中的一个节点,定义gp->p, c->gc1,…,c->gc_n(gp表示grandparent节点,c表示child节点,gc表示grandchildren节点)为上下文关系
-
attention over child embeddings( $ ATT_CE $)
通过self-attention可以计算得到每个子节点的hidden representation
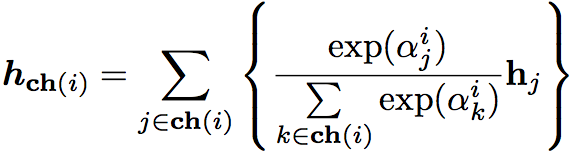
其中attention coefficient为
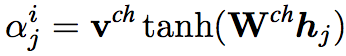
上式中的v和W均为模型参数
所有子节点的hidden representation通过一个GRU,输出为父节点的表示
4.2 Augmented Relation Classification
对于一个实体对对应的N个句子(Bag),可以得到
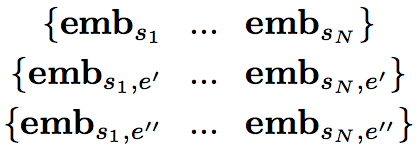
第一行中的每一个对应着bag中一个句子的embedding
第二行中的每一个对应着bag中一个句子的第一个实体的embedding(由上述过程得到)
第三行中的每一个对应着bag中一个句子的第二个实体的embedding
-
Attention over entity embeddings (ATT_EE)
得到的三种embedding都通过self-attention(同ATT_CE中的attention方法,参数不同)得到对应的hidden representation
-
The concatenation strategy (CAT)
将hidden representation连接,并通过一个线性层,得到一种relation score vector
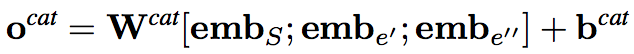
-
The translation strategy (TRANS)
受到TransE的启发,使用两个实体的embedding之间的差进过线性变换可以得到另一种relation score vector
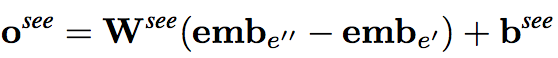
最后的结果结合了两种relation socre vector
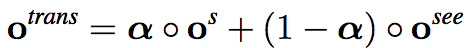
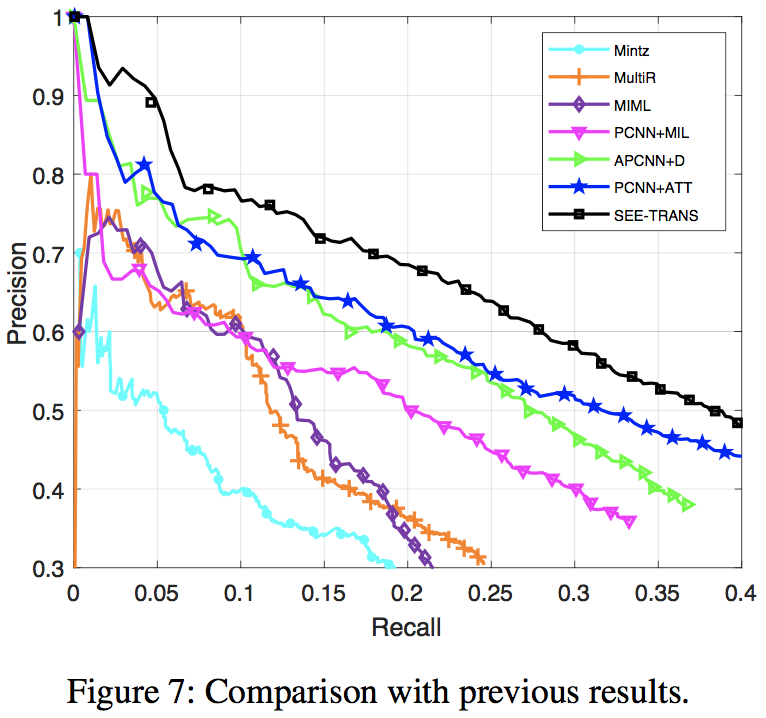
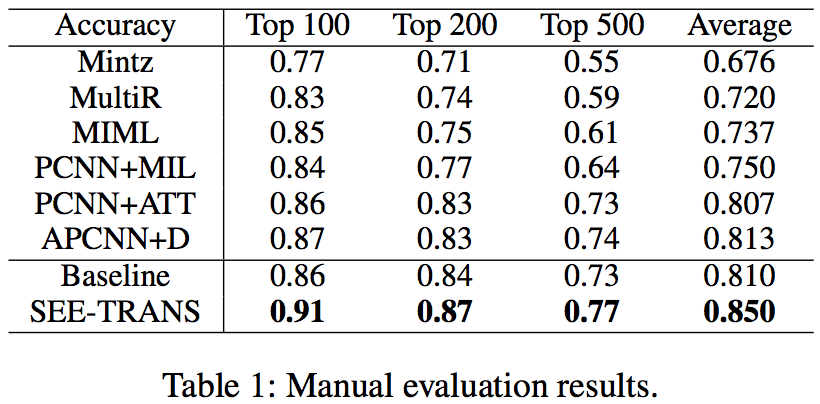
5. 实验结果
实验在freebase监督下的NYT(2005-2007)的数据上进行,其结果如下
6. 个人总结
这篇文章的一个很有意思的想法在于通过语法树来获取得到entity的embedding,从之前的relation classification的工作来看,entity的embedding是一个很重要的特征,但是在之前的工作中,大多直接使用输入sequence的embedding层来同时处理entity,这种方式有两个缺陷:1. entity比较独有,可能发生OOV。2. entity有时是一个序列(多个词),但是通常会直接取最后或者最前一个词的embedding作为entity的embedding。这篇文章首先,直接在目标数据集上训练了新的embedding,训练过程中使用了一种新的上下文定义,但文中没有对这种embedding的效果进行单独的测试,也无从知道其对效果的影响有多大。另外一点值得注意的是,这篇文章中使用了较多的attention机制,这一点也说明了attention在实际中的效果还是很好的