来源
ACL 2017
作者信息

概要
神经网络模型通常使用共享层来实现多任务学习,但是对于大多数的方法,网络提取得到的共享特征可能被任务特有(task-specific)的特征影响。为了解决这个问题,本文提出了一种对抗多任务学习(adversarial multi-task learning)的模型,来减轻共享特征和任务特有特征的相互影响。本文在16个不同的问本分类任务数据集上进行了实验,取得了不错的效果
介绍
大多数的多任务学习任务将不同任务的特征分隔到私有特征空间和共享特征空间。这种做法的缺陷在于,这种特征分割并不是很完美的,共享特征空间可能包含一些私有特征,而私有特征空间也可能因为冗余特征而包含一些共享特征,如下图所示
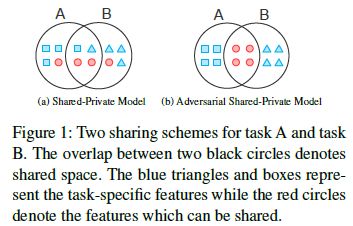 为了减少私有特征和共享特征之间的相互影响,本文中提出了两种策略:
为了减少私有特征和共享特征之间的相互影响,本文中提出了两种策略:
- 对抗训练(adversarial training)。保证共享特征空间中仅包含不同任务的私有特征
- 正交限制(orthogonality constraint)。减少共享特征空间和私有特征空间的冗余特征
多任务文本建模有很多的模型,一种典型的模型如下所示:(本文的模型在此模型上进行改进
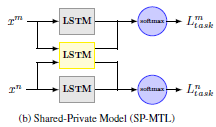
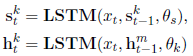
模型中,使用不同的LSTM处理任务的私有特征和共享特征
模型
在基础模型上,本文提出的模型通过在目标函数中添加额外的损失项来实现对抗训练和正交限制 整体的模型如下所示
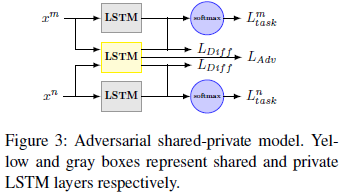
下面分别介绍这两种损失项
-
对抗训练 $ L_{Adv} $
受到GAN(Goodfellow et al., 2014)的启发,本文模型中引入了一个对抗网络,来区分私有特征和共享特征,使得通过共享特征对任务类型的判断是不准确的,从而鼓励共享特征不包含私有特征
shared recurrent neural layer is working adversarially towards a learnable multi-layer perceptron, preventing it from making an accurate prediction about the types of tasks
模型中使用一个简单的softmax作为对抗网络,
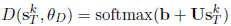
$ L_{Adv} $ 用来训练模型,使得模型产生的共享特征不能被对抗网络用来准确地预测问题的类型(从而保证共享特征空间中仅包含不同任务的私有特征) 由于包含多个任务,模型扩展了GAN地原始公式到多分类地形式
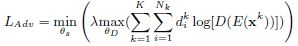
其中 $d_i^k$ 表示任务的实际类型(ground-truth label),整个公式是一个minmax game,对抗网络$ D $被训练以最大化分类的准确率,而‘生成网络’$ E $(这里指模型中共享特征对应的RNN层)被训练以最小化最终分类的准确率
注意到,$L_{Adv}$ 的训练只依赖于训练数据x,而不依赖任何标签,这使得整体的模型可以通过半监督的方式进行训练
-
正交限制 $ L_{Diff} $
Follow (Jia et al., 2010; Salzmann et al., 2010; Bousmalis et al., 2016)的工作,本文引入了正交限制$ L_Diff $ 衡量共享特征和私有特征之间的相似度
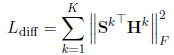
其中 $| ∗ |_F^2 $是squared Frobenius norm。$S^k$ 和$H^k$ 是两个矩阵,其中的行分贝为共享特征和私有特征(RNN提取的结果)
最终的目标函数为
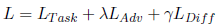
实验结果
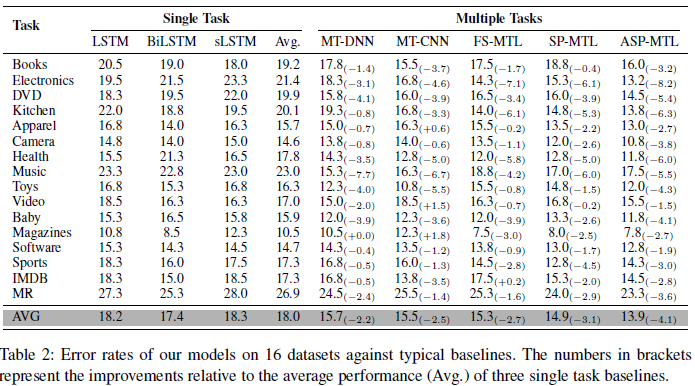 (其中FS表示full-share,sp表示share private,asp表示adversarial share private)
(其中FS表示full-share,sp表示share private,asp表示adversarial share private)
在所有任务上,ASP-MTL都能够有效地提升分类地效果 为了测试模型中对抗训练地效果,本文进行了如下地实验
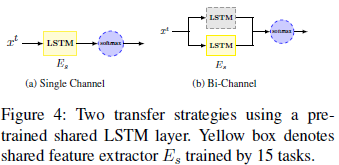
结果如下所示
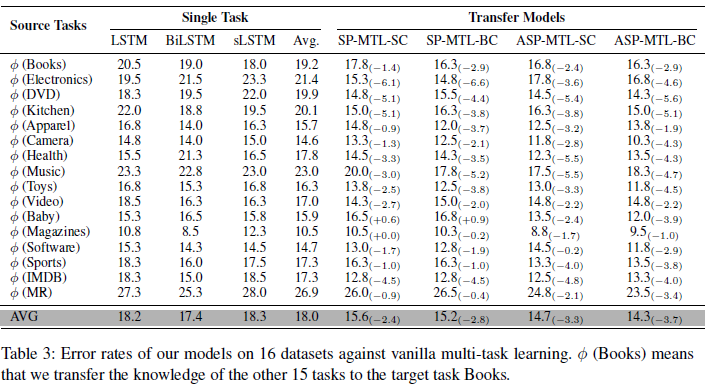
可见ASP-MTL效果优于SP-MTL,而BC地效果好于SC
个人总结
这篇论文提出的模型是有效的但也是复杂的,在比传统多任务学习方法提高了1~2%准确率的同时,引入了两个额外的Loss,并且由于使用了minmax game的训练模型,势必会增加训练的难度和时间。 这篇论文提出的模型的另一个优势在于引入adversarial training带来的无标签数据的利用,但是论文的实验部分并没有对此进行实验;此外本文没有进行ablation测试,展示 对抗训练和正交限制 单独的效果 这篇论文的想法是富有新意的,通过对抗学习来将共享特征和私有特征区分开来,这种想法还能继续扩展开来,对于一些用普通的损失函数难以描述的指标,都能够通过对抗网络来进行更好的描述。
-
前一篇
SEE: Syntax-aware Entity Embedding for Neural Relation Extraction -
后一篇
Unsupervised Machine Translation Using Monolingual Corpora Only