1. 来源
CVPR 2016
2. 作者信息
Joseph Redmon∗†, Ali Farhadi∗† University of Washington∗, Allen Institute for AI† http://pjreddie.com/yolo9000/
3. 概要
本文提出的YOLO9000模型能够准确地、实时地对9000种物体进行检测。本文首先介绍了对YOLO的几种改进方式,改进的模型,YOLOv2,能够达到非常高的准确率。之后本文介绍了一种多尺度的训练方法,使得模型能够在准确率和运行速度之间进行均衡。最后,本文提出了一种物体检测和分类的联合学习算法,得到的模型YOLO9000能够检测9000种不同的物体
4. Better
YOLO和Fast R-CNN相比有明显的短处。从YOLO的错误分析种可知,相比于Fast R-CNN,YOLO对bounding box位置的预测误差较高,并且YOLO预测结果种的recall较低。因此对YOLO的改进主要在于在保持准确率的同时改进recall和位置预测
4.1 Batch Nomalization
Batch Normalization能够起到正则化的作用,并且显著地加快网络的收敛速率。通过在YOLO的网络中所有的卷积层前添加BN层,能够得到2%的mAP的提升
4.2 High resolution classifier
YOLO的训练过程中先使用224224的图片训练分类网络,然后使用448448的图片训练目标检测网络,这意味着在训练过程中,模型需要同时转移到目标检测任务并且适应更高分辨率的输入
YOLOv2中,直接使用448448的图片训练分类网络,然后再用448448的图片训练目标检测网络,通过这种方式,可以得到4%的mAP的提升
4.3 convolutional with anchor boxes
在YOLO中,每一个小格会预测得到2个不同的bounding box以及类别标签、IoU,而在YOLOv2中,每个小格会产生得到多个不同的anchor,并且每个anchor会单独地预测类别标签以及IoU。通过使用anchor,YOLOv2预测得到的bouding box超过1000个,相比之下,YOLO预测得到的bounding box只有98个。通过这种方式,在损失部分mAP(69.5%->69.2%)的同时,增加了recall(81%->88%)
此外,YOLOv2的输入从448448(对应1414的feature map大小)修改到416416(对应1313的feature map大小),这样的原因在于,多数图片中的物体位于中心,而YOLO从物体中心所在的格子计算得到bounding box,使用奇数大小的feature map可以使得最终原始图片的中心只落在一个单独的格子里(相比之下,如果使用14*14的feature map,会落在4格格子里)
4.4 dimension clusters
在YOLO中使用anchor有两个问题,其一是anchor的大小的选择。bounding box预测网络能够预测得到bounding box的位置,但是如果使用合适的anchor作为先验,能够有效地提升预测的效率。这里没有人工定义anchor的大小,而是通过对训练集中的bounding box进行聚类得到anchor。由于bounding box的大小会对欧式距离的结果产生影响,而这里是希望能够得到更好的IoU分数,因此,可以使用下式计算距离
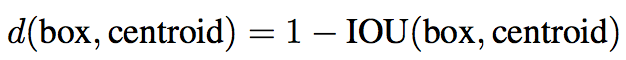
聚类的结果如下
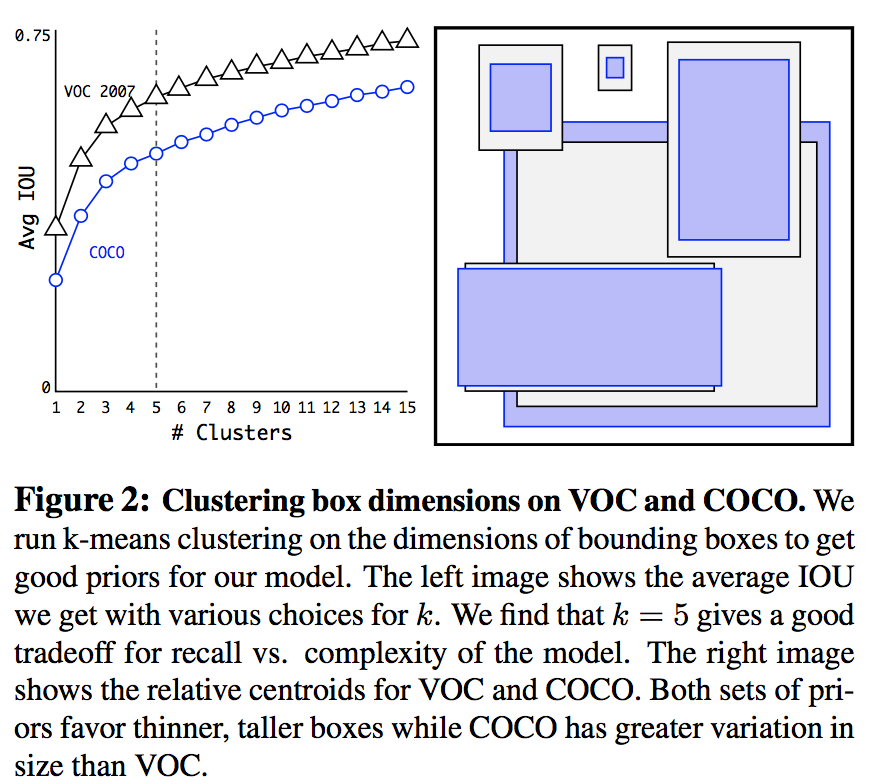
最终本文选择了k=5
4.5 Direct location prediction
在YOLO中使用anchor的另一个问题在于模型的稳定性,这一点在训练初期尤为显著。而不稳定的主要来源是位置偏移量的预测
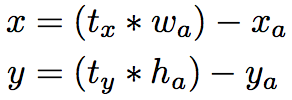
如果预测结果t_x 的偏差为1,则会造成bounding box水平方向平移一整个anchor的水平方向大小
YOLOv2中修改了bounding box位置的计算方式为
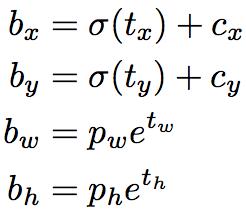
c表示格点的位置
过程如下图所示
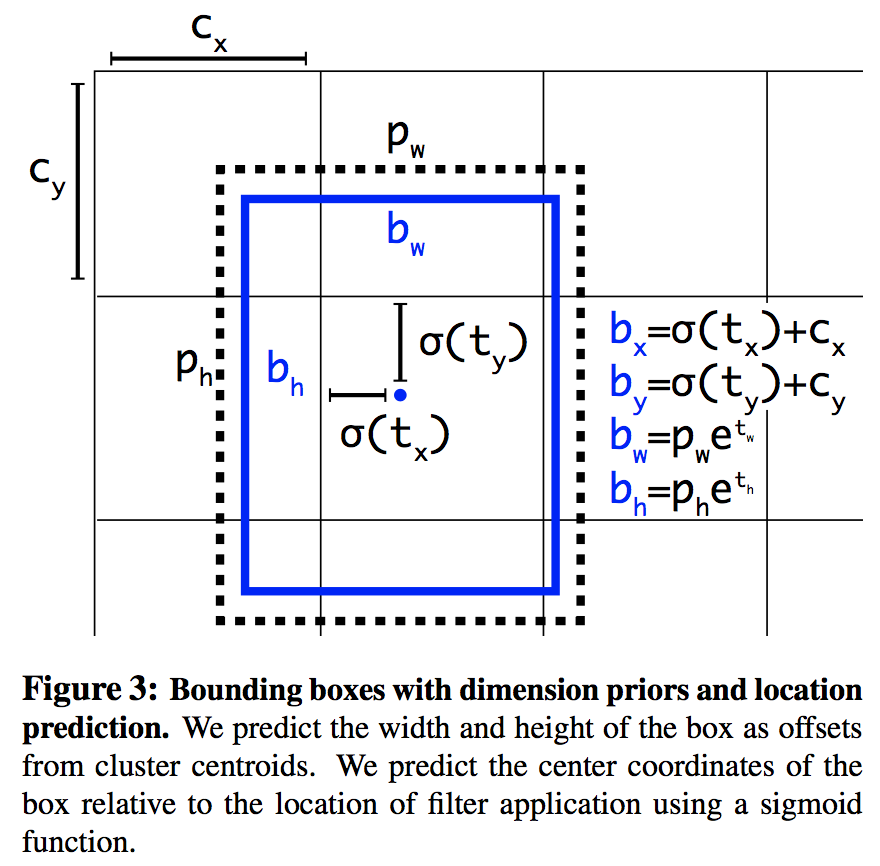
可见,采用这种方式,bounding box位置的偏移量最多为anchor的大小
4.6 Fine-Grained Features
YOLO只使用最后一层卷积层的feature map来预测bounding box,由于卷积操作是一个downsampling的过程,一些细节会损失,这样虽然对一些较大的物体的检测不会产生影响,但是对一些较小的物体的检测会受到影响,YOLOv2中同时利用最后一层卷积层的feature map(1313)以及倒数第二层的卷机层的feature map(2626)进行预测,具体的做法是将倒数第二层的卷机层的feature map进行reshape,然后和最后一层卷积层的feature map进行连接
4.7 Multi-Scale Training
注意到YOLO中只使用到了卷积层和池化层,因此YOLO可以直接处理任意大小的输入图片,为了让YOLO能够对图片的大小有更强的鲁棒性,YOLOv2在训练过程中使用不同大小的输入图片进行训练。每隔10个batch,修改输入图片的大小。通过这种方式,可以对模型的速度和准确性进行tradeoff,当输入的图片较小时,速度快,但是准确率低,当输入的图片较大时,速度慢,但是准确率高
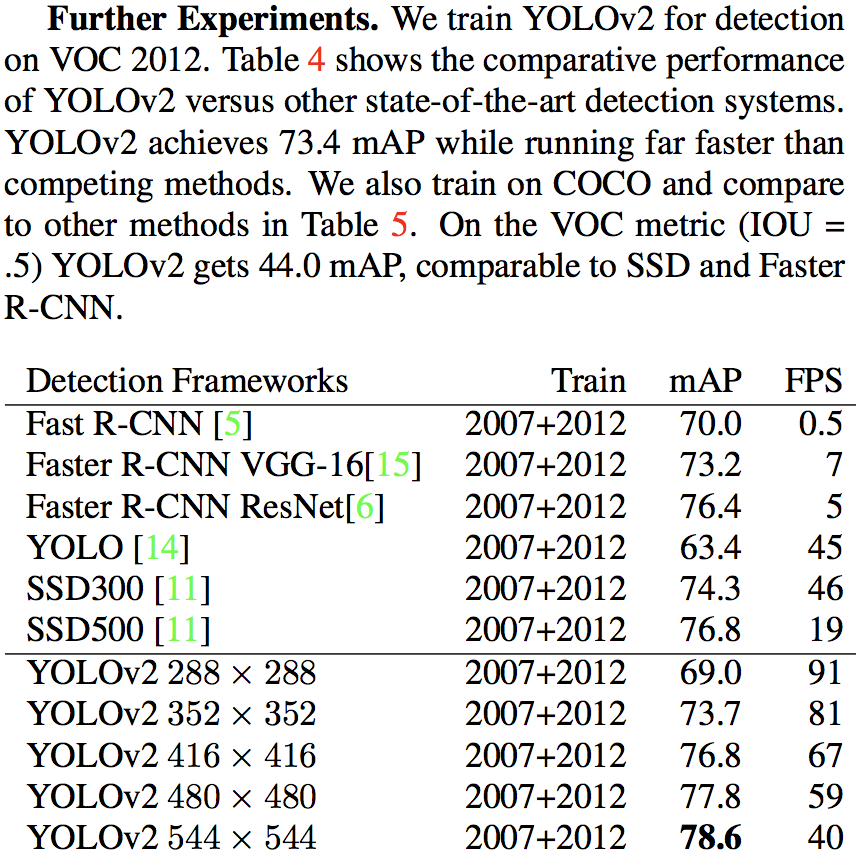
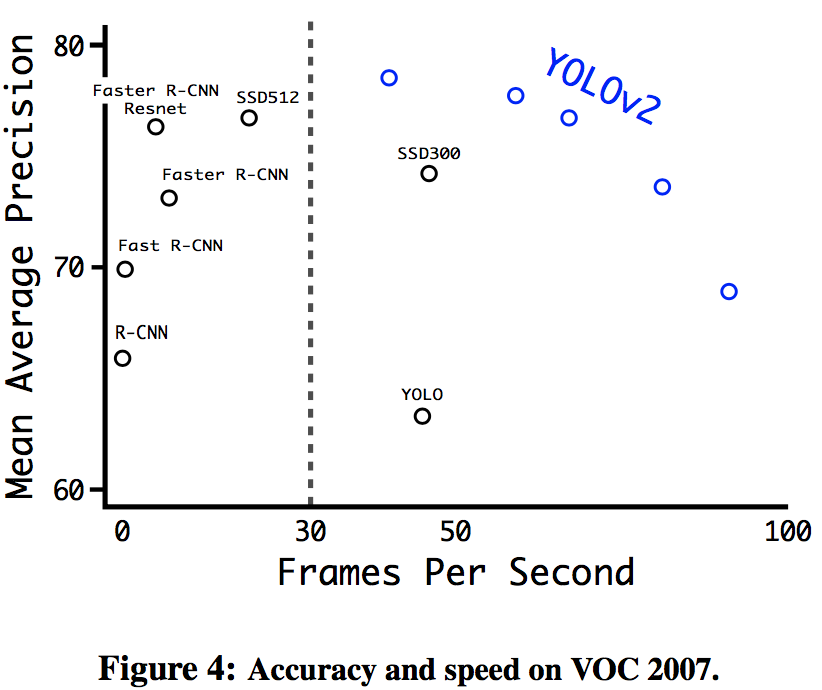
5. Faster
YOLO使用了一个类似于Google-net的网络结构,一次inference过程需要8.52亿次计算,而在YOLOv2中,使用了Darknet-19,相比于YOLO中的网络,Darknet-19的计算量更少,但是分类的精度更高,其结构如下所示
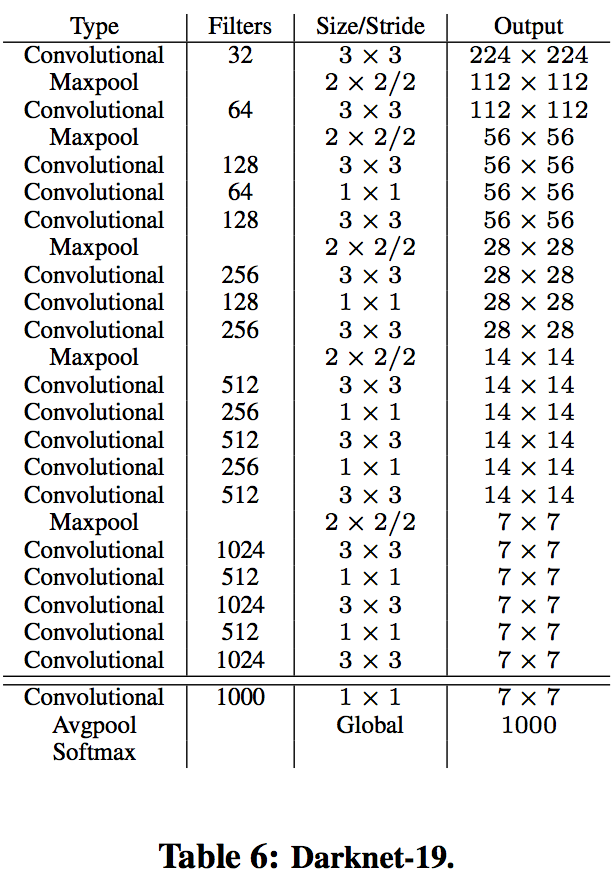
5.1 Training for classification
在标准1000类的ImageNet上训练了160个epoch,用SGD进行训练,初始learning rate 为0.1,polynomial rate decay 为4,weight decay为0.0005 ,momentum 为0.9。训练的时候使用了常见的数据扩充方法(data augmentation),包括random crops, rotations, and hue, saturation, and exposure shifts。
5.2 Training for detection
将网络的最后一层替换为33 conv (滑动窗口)+ 11 conv(作用是对窗口内数据做一个FC)。共训练160个epoch,用SGD进行训练,初始learning rate 为0.001,在第60和第90 epoch将learning rate降低10倍,weight decay为0.0005 ,momentum 为0.9。训练的时候使用了常见的数据扩充方法
6. stronger
最后使用分类数据和检测数据一起进行训练集,输入的数据被标记为分类数据或者检测数据,当数据为分类数据时,使用分类的loss function训练,否则,使用检测的loss function训练。但是这样会有个问题,检测数据通常的标签是一些比较general的标签,如狗,但是分类标签中会有一些更为细节的标签,如“某品种的狗”。所以必须使用某种方法来整合这些标签
6.1 hierarchical classification
使用wordnet中词语的上下位关系来整合标签,但注意到wordnet中标签的关系并不是树形结构,为了似的最终标签的结构是一个树形结构,对于wordnet中的两个标签,只使用它们之间的最短路径,最终能够得到一个wordtree
根据wordtree可以进行多标签的分类
而模型的分类结果相应地转变为wordtree中每个节点的分类结果,例如对于节点’terrier’,预测的值为

在训练阶段,标签类别在wordtree中所有的祖先节点均标记为正确,然后进行训练
而在测试阶段通过概率的乘积计算节点最终的概率,例如通过以下公式可以计算一张图片是否是”Norfolk terrier”

因此在YOLOv2预测的输出是一系列较小分类的softmax结果,如下所示
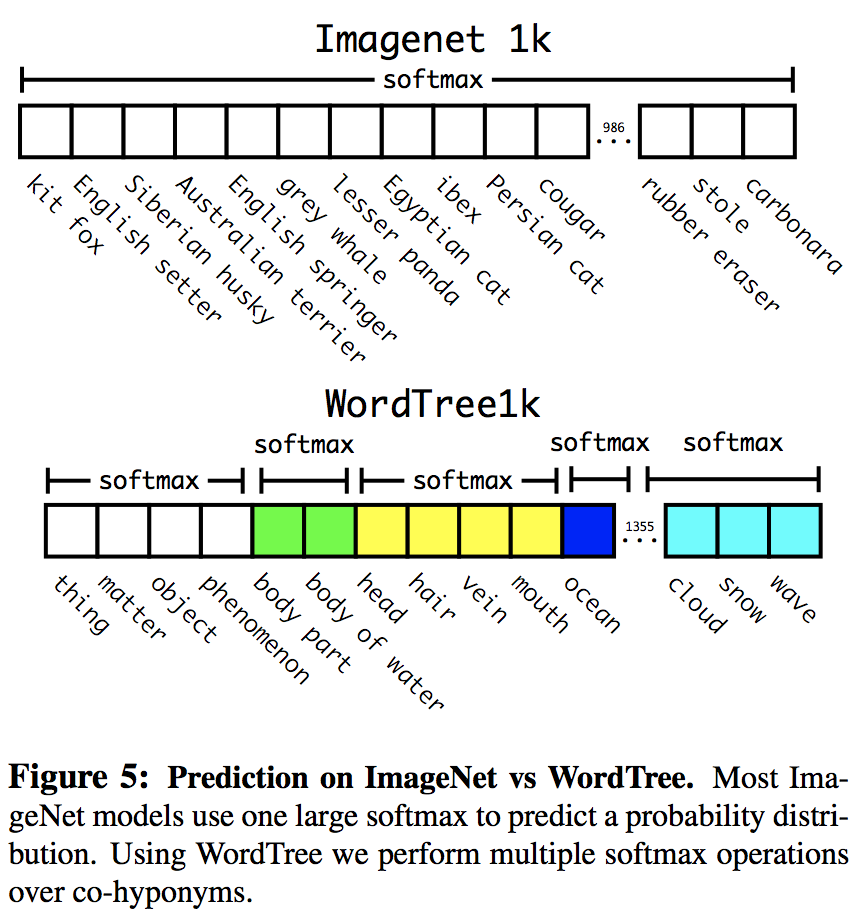
6.2 Dataset combination with WordTree
通过wordtree,还能够融合使用多种不同数据集数据,只需要将数据集中的标签和wordtree中的节点映射即可,下图为COCO和ImageNet的组合过程
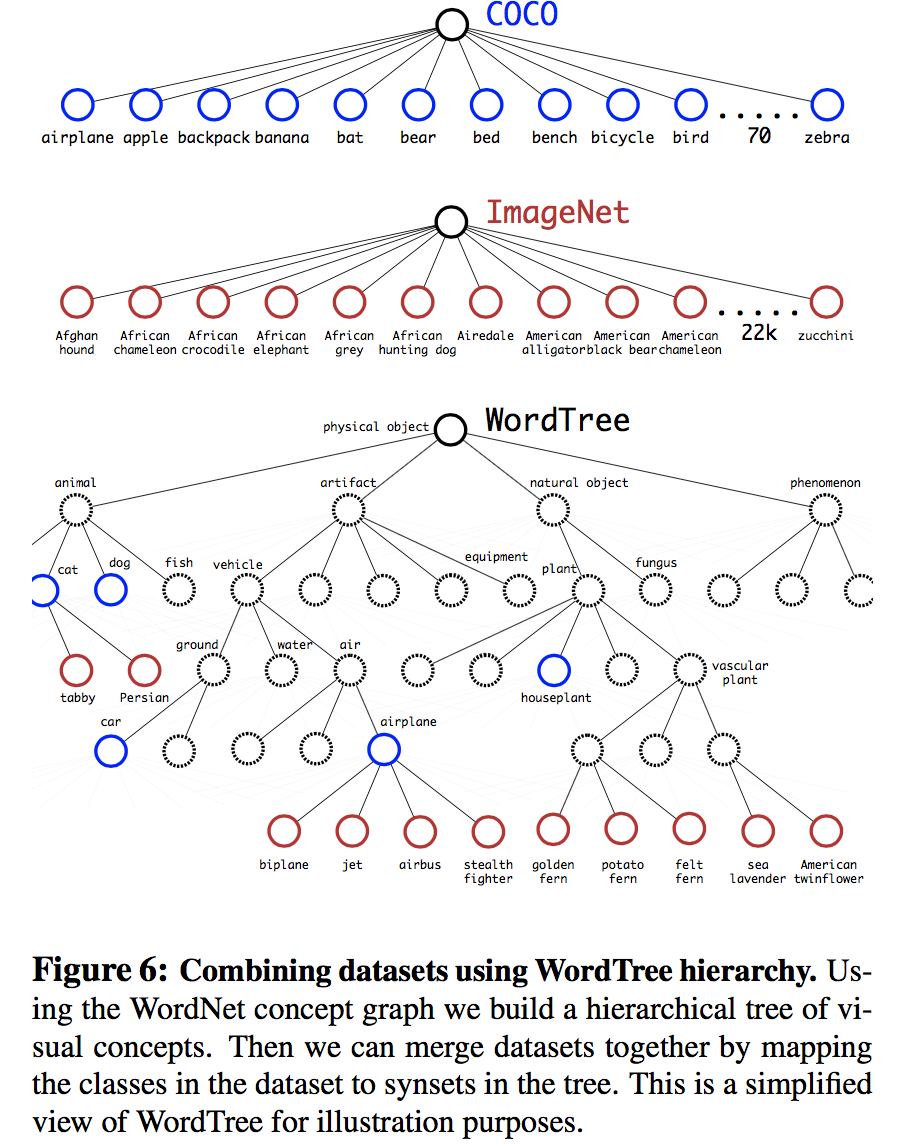
6.2 Joint classification and detection
使用COCO数据集以及ImageNet的9000个类别标签,对应的wordtree的节点数为9418,这些数据(对COCO进行过采样,使得COCO和ImageNet的数据的比例约为4:1)可以用来训练YOLO9000,anchor的数量从k=5减少到k=3以限制输出的数量
-
前一篇
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks -
后一篇
SEE: Syntax-aware Entity Embedding for Neural Relation Extraction